
Decision Trees
Entropy:
The level of uncertainty or randomness in a set is known as its entropy. It describes the distribution of a dataset. If a dataset consists of a single class, then its entropy will be zero as it has no uncertainty. If every class in the dataset has equal probability then the entropy of the dataset will be maximum.
Let’s try to understand it through an example:
Suppose we have a dataset S having C number of distinct classes. Let p(c) be the probability that a data belongs to class c, where c∈(1,2,3,…,C).
Then the entropy can be defined as follows:
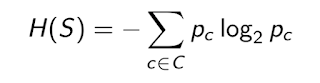
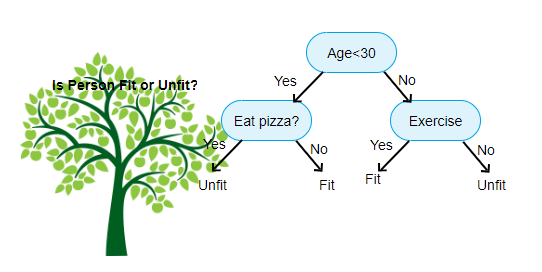
Now, let’s look at a simple decision tree given at the top of the blog:
As we keep going down the tree, we get close to be certain to make a decision. Now at the node of the tree, which is a rule we want maximum certainty, meaning minimum entropy.
In simple words, we want to start with a rule which gives us maximum information gain.
A feature is said to be more informative if, by knowing its value, the entropy of dataset reduces more.
Let us take an example:
The dataset ‘S’ contains features{outlook, Temperature,Humidity}. Suppose we split our dataset based on the feature Temperature{Hot,Cold}. Now the information gain given the value of Temperature will be:
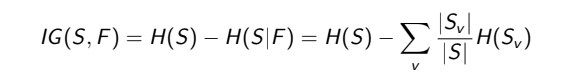
where v∈(Hot, Cold). Similarly, we calculate the value of IF for other features: Humidity and Outlook and the feature with maximum information gain will be kept as the root node. We can do a similar process on the splits we got to decide other nodes in the tree.
If the entropy of any split becomes zero then, it becomes a pure class and there is no need to split further. But we can have a threshold for the entropy below which we can stop splitting. Having a threshold greater than 0 helps us get rid of overfitting.
We can visualise the effect of information gain on the splits in the figure given below:
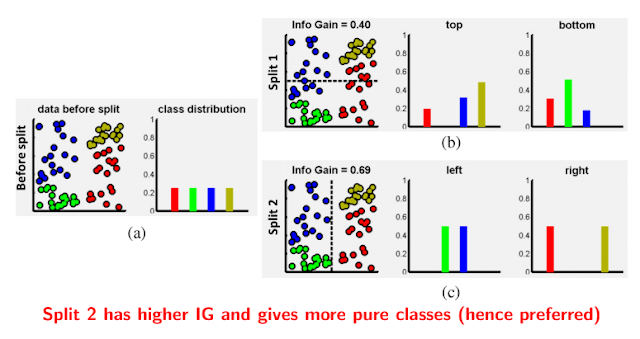
We have learned how to construct a decision tree and we can use it for different but mainly classification purposes.
Keep Learning, Keep Sharing😊.