
Reinforcement Learning : Deep Q Networks
In the previous two blogs, I went through the basics of Q-learning, building a simple RL Agent using q-table and creating a custom environment for our own use case. But as we keep making the environment bigger and complex, the q-table becomes bigger in size and this causes a scaling problem. I studied about Deep Q-learning which solves this problem and I will be going through the topic in detail in this blog.
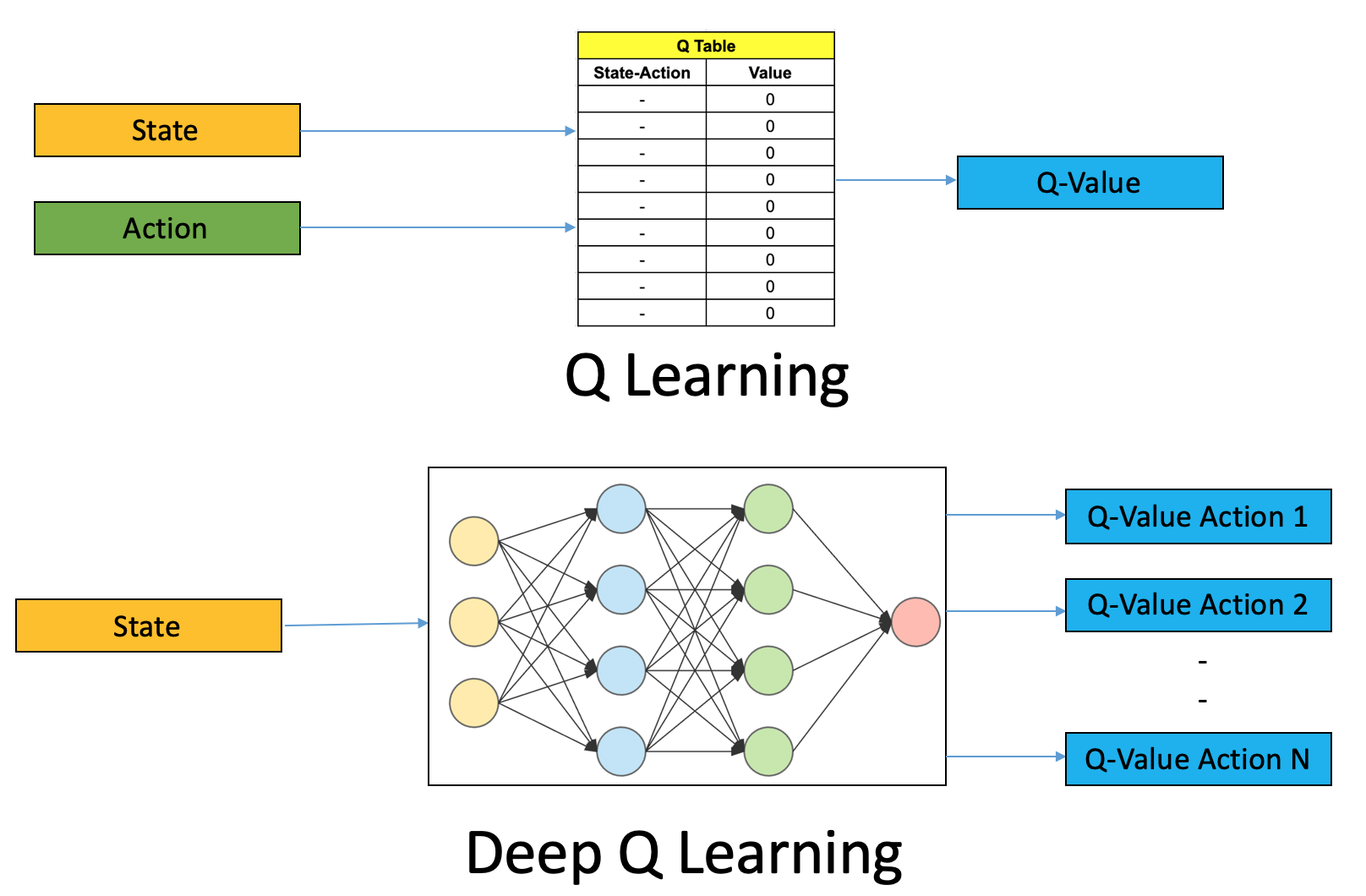
We will be making use of the fact that neural networks are very good function approximators. You just need to have some weight values and can approximate various complex functions. The q-tables discussed previously, were used to store some values for all possible actions given a particular state. Based on those values, we used to decide which action to take further. Now instead of storing those values, we can train a neural network which predicts the action to take in the future, given the current state. This can prove to be a relief for the scaling problem. We will be creating a deep Q-Agent using CNNs and will feed input as images of the states in it.
The Q-Agent class will contain two models, one for training and one for prediction. We will keep track of a limited number of past steps of the agent as we need to feed the data in batches(well, batch_size can be one too but it’s always better to use mini-batches).
Given below is the code for the Q-Agent class.
class DAgent():
def __init__(self):
self.train_model = self.create_graph()
self.predict_model = self.create_graph()
set.predict_model.set_weights(self.train_model.get_weights())
self.train_data = deque(maxlen=20000)
self.set_predict_model_count = 0
def create_graph(self):
model = Sequential()
model.add(Conv2D(100,(3,3)), input_shape=env.observation_space_shape)
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(50, (2, 2)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128))
model.add(Dense(env.action_space_n, activation='linear'))
model.compile(loss="mse", optimizer=Adam(lr=0.001), metrics=['accuracy'])
return model
def update_train_data(self, transition):
self.train_data.append(transition)
def train(self,terminal_state, step):
if(len(self.train_data)<min_train_data):
return
batch = random.sample(self.train_data, batch_size)
current_states = np.array([transition[0] for transition in batch])/255
current_q_values = self.train_model.predict(current_states)
new_states = np.array([transition[3] for transition in batch])/255
new_q_values = self.predict_model.predict(new_states)
X = []; Y = []
for index, (current_state, action, reward, new_state, done) in enumerate(batch):
if not done:
max_future_q_value = np.max(new_q_values[index])
new_q = reward + DISCOUNT * max_future_q_value
else:
new_q = reward
# Update Q value for given state
current_q_value = current_qs_list[index]
current_q_value[action] = new_q
# And append to our training data
X.append(current_state)
Y.append(current_q_value)
self.train_model.fit(np.array(X)/255, np.array(Y), batch_size=batch_size, verbose=0)
if(terminal_state):
self.set_predict_model_count +=1
if(self.set_predict_model_count%5==0):
self.predict_model.set_weights(self.train_model.get_weights())
save_model(predict_model, 'deepQLearning.h5')
def get_q_value(self, state):
return self.train_model.predict(np.array(state).reshape(-1, *state.shape)/255)[0]
We will be using the same Grid which we used in the previous blog for creating our custom environment which is as follows:
import numpy as np
from PIL import Image
import cv2
import pickle
import time
SIZE = 10
class Grid:
def __init__(self,size=SIZE):
self.x = np.random.randint(0, size)
self.y = np.random.randint(0, size)
def subtract(self, other):
return (self.x-other.x, self.y-other.y)
def isequal(self, other):
if(self.x-other.x==0 and self.y-other.y==0):
return True
else:
return False
def action(self, choice):
'''
Gives us 8 total movement options. (0,1,2,3,4,5,6,7)
'''
if choice == 0:
self.move(x=1, y=1)
elif choice == 1:
self.move(x=-1, y=-1)
elif choice == 2:
self.move(x=-1, y=1)
elif choice == 3:
self.move(x=1, y=-1)
elif choice == 4:
self.move(x=1,y=0)
elif choice == 5:
self.move(x=0, y=1)
elif choice == 6:
self.move(x=-1, y=0)
elif choice == 7:
self.move(x=0, y=-1)
def move(self, x=False, y=False):
if not x:
self.x += np.random.randint(-1, 2)
else:
self.x += x
if not y:
self.y += np.random.randint(-1,2)
else:
self.y += y
if self.x<0:
self.x=0
if self.x>=SIZE:
self.x = SIZE-1
if self.y<0:
self.y=0
if self.y>=SIZE:
self.y = SIZE-1
Since we are using deep neural network here and we need to store various states for the training, we will be creating a Grid_env class very similar to that of a gym environment which returns the new state, reward and the done value, so that it becomes more structured and easy to handle. This class will have reset, step and render functions similar to that of gym and an extra return_img function for the data of the deep-learning model we created above.
Let us create an environment class:
class Environment():
### class variables
SIZE = 15
RETURN_IMAGES = True
MOVE_PENALTY = -1
ENEMY_PENALTY = -300
FOOD_REWARD = 25
observation_space_shape = (SIZE, SIZE, 3) # 4
action_space_n = 8
PLAYER_key = 1
FOOD_key = 2
ENEMY_key = 3
# the dict! (colors)
d = {1:(255, 0, 0), 2:(0,255,0), 3:(0,0,255)}
####################
def reset(self):
self.player = Grid(self.SIZE)
self.enemy = Grid(self.SIZE)
while(self.player.isequal(self.enemy)):
self.player = Grid(self.SIZE)
self.food = Grid(self.SIZE)
while(self.food.isequal(self.enemy) and self.food.isequal(self.player)):
self.food = Grid(self.SIZE)
self.ep_step = 0
observation = np.array(self.return_img())
return observation
def step(self,action):
self.ep_step +=1
self.player.action(action)
new_observation = np.array(self.return_img())
if(self.player.isequal(self.enemy)):
reward = self.ENEMY_PENALTY
elif(self.player.isequal(self.food)):
reward = self.FOOD_REWARD
else:
reward = self.MOVE_PENALTY
if(self.player.isequal(self.enemy) or self.player.isequal(self.food) or self.ep_step>=200):
done = True
else:
done = False
return new_observation, reward, done
def render(self):
img = self.return_img()
img = img.resize((400, 400))
cv2.imshow("image", np.array(img))
cv2.waitKey(1)
def return_img(self):
env = np.zeros((self.SIZE, self.SIZE, 3), dtype=np.uint8)
env[self.food.x][self.food.y] = self.d[self.FOOD_key]
env[self.enemy.x][self.enemy.y] = self.d[self.ENEMY_key]
env[self.player.x][self.player.y] = self.d[self.PLAYER_key]
image = Image.fromarray(env, 'RGB')
return image
Now comes the training part. We will train the agent for 50000 episodes and render the environment every 1000 episodes. The code for training will look as follows:
agent = dqAgent()
env = Environment()
episodes = 50000
eps_rewards = []
for ep in episodes:
ep_reward = 0
ep_step = 1
current_state = env.reset()
done = False
while not done:
action = np.random.randint(0, env.action_space_n)
new_state, reward, done = env.step(action)
ep_reward += reward
if(ep%1000==0):
env.render()
agent.update_train_data((current_state, action, reward, new_state, done))
agent.train(done, step)
current_step = new_step
step += 1
eps_rewards.append(ep_reward)
I have also created a list which stores the reward for each episode which when plotted, ideally should be an increasing graph. I have enabled the player only for the movement but we can play around with it and enable enemy and food also. We can also increase the number of food and the thiefs to make the game more challenging. It would be more cool, if we change the entire environment and create a new game itself. Meanwhile, we have successfully created a deep QAgent for cool RL games. In the upcoming blogs, We will be studying and implementing some interesting RL Algorithms proposed and used by DeepMind and OpenAI. A huge credit for the past blogs goes to sentdex for creating such nice tutorials.
Keep Learning, Keep Sharing 😊