
Unsupervised Image Segmentation
So, Just adding to the regular "Learn and Share" blog thread,
we will go through the topic of Unsupervised Image Segmentation
in this blog.
What is segmentation?
So, what exactly is image segmentation? We will understand that
through an image given below:
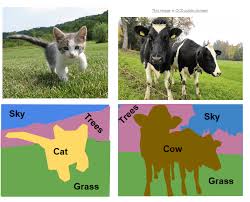
As, you can see from the picture, segmentation can be understood
as grouping the pixels together which have similar attributes.
The attributes can be colour, brightness, intensity etc. Thus,
it can be seen that the pixels describing the cat have been given
the same category, and so is for the pixels describing the grass,
cow, trees respectively.
How to do segmentation?
As study in machine learning has advanced this far, we have many
methods for this problem. So, generally we have a dataset containing
images and we also have the annotations of each image containing the
label and boundary boxes for each object in the image file. Using the
annotations, we can train the dataset on a deep learning network to
learn to predict the segmentation of a newly given image.
But, what if the annotations are not given?
This type of problems can be put in the category of unsupervised learning.
So, we are going to discuss two methods to segment an image if we have an
unsupervised dataset.
Method 1 : (Based on Back-propagation)
Let me first show you the structure of the model and then we will go into
the details:
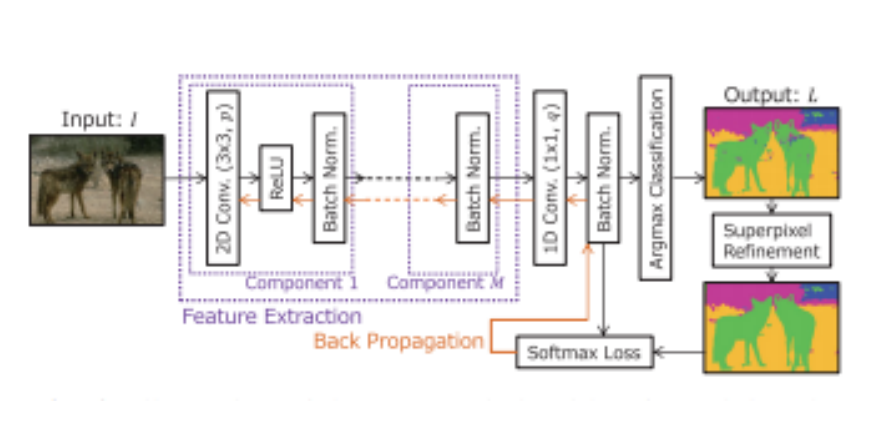
Given a RGB image, we can consider every pixel of the image as a 3x1 vector,
i.e., the [R,G,B] values. So, each pixel of the image is passed through a
convolutional neural network to obtain its high level feature vector. These
feature vectors can be further used to do k-mean clustering with the help of
which we assign labels to each pixel.
Let 'x' be the feature vector for a particular pixel in the image and 'f(x)'
be a function which predicts the cluster label 'c' for the pixel. Now we have
three things : 'x',' f(x)' and 'c' which need to be trained. This is done by
alternately fixing the parameters for two things and training the third
function at a time. For example, if 'c' is being predicted, we keep the parameters
for 'x' and 'f(x)' constant. The weights or parameters are updated using
back-propagation method using stochastic gradient optimiser.
For good segmentation, certain characteristics are required for the cluster label 'c'.
Instance of any object contains patches of similar texture patterns. So, we should
take this in account while performing segmentation. Hence, spatially continuous pixels
that have similar colour and texture patterns should be grouped together. On the other
hand, different object instances should be categorised separately. To facilitate this
cluster separation, the number of cluster labels is desired to be large(>2).
Method 2 : (Domain Adaptation Based)
In this method, knowledge transfer or domain adaptation is done to close the gap of
distributions of source and target domains. Based on the General Adversarial Network,
this model consists of two parts:
Segmentation Network to predict the segmentation of the images, and the Discriminator
network to tell whether the input image is from source domain or target domain. For example,
I used the GTA game dataset as the source domain and the IIT Kanpur surveillance dataset
as the target domain to train the model.
The model architecture is given as follows:
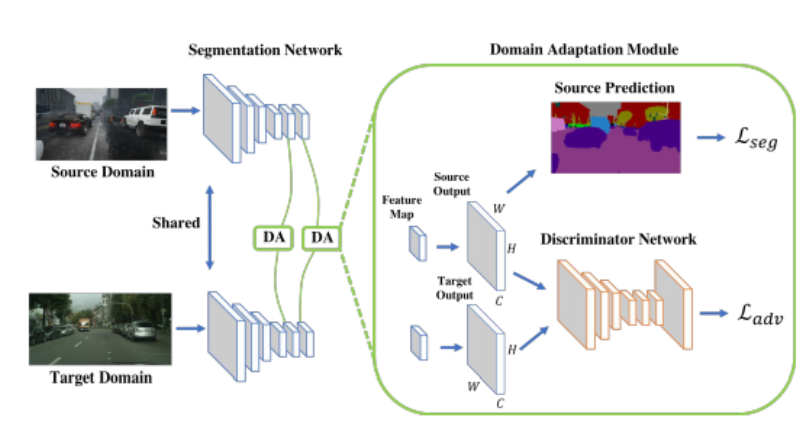
On the one hand the loss for the segmentation is minimised while simultaneously, the loss
for the discriminator network is maximised so that it becomes difficult for the discriminator
network to distinguish between the source and the target domains and thus the segmentation network
can easily use the transferred knowledge from the GTA dataset(which is labelled) to predict
the segmentation for the IIT Kanpur dataset.
Results :
Column1 : Input Image
Column2 : Method1
Column3 : Method3

I hope the blog was informative enough.
Keep Learning, Keep Sharing 😊