
Visual Question Answering in Deep Learning
![]()
As research in machine learning has advanced so far and so has this blog 😃, we will be discussing the topic of visual question answering in this blog. As the name suggests, we will be given an image as the knowledge domain and a text-based question will be asked. Based on all these we will have to answer that question.
**We will be building our model from scratch and also discuss upon improvising the same.
The model structure will be as follows:**
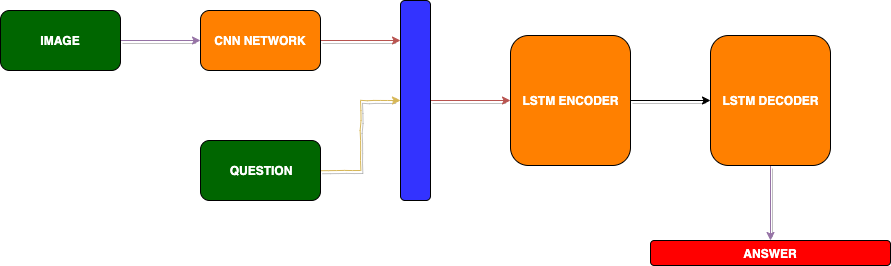
DATASET:
There are a lot of datasets we can work upon but currently, our main focus is to be able to build a deep learning model for answering the queries based on an image.
As of now, we will make an assumption about the dataset that it contains a pre-processed image of size 50x50 pixels and the question has a maximum length=10 words and has an answer of maximum length=5 words.
Let us define the various parameters first:
Here VOCAB_ANS_SIZE is a separate vocab which is smaller in size as compared to the actual vocab so as to reduce the computation. We should build a separate vocab which consists of words from the answers in the training data only.
Now, let us build the Image encoder:
We will use repeat vector for the encoded image vector so that we embed the image information to each of the words of the question by concatenating the image vector to each word of the question sequence.
Let us now build the encoder for the question+image:
We will feed the last state of the encoder as the initial_state in the decoder layer. Below is the code for decoder layer which finally computes the probability of 5 words in the answer from the VOCAB_ANS.
Now we are ready with the architecture and we can define our final model and loss functions as follows:
Since we are using sparse categorical cross_entropy function as our loss function, we don’t need to send the output as one-hot vectors.
Note: The confusing point, decoder inputs are nothing but a sequence of UNKNOWN_TOKENS of length=5words. This is to initialise the decoder layer. We need to pass that separately to the model while training and prediction.
Finally, we are ready with a visual question answering model building it from scratch. We can improve the image encoding by using Transfer-learning and passing the image to a pre-trained model like Inception, VGG, Resnet etc to obtain better image feature.
Hope you like reading this blog.
Keep Learning, Keep Sharing 😊.