
Extrapolating to longer sequence lengths using ALiBi

One of the core components of transformer models is the attention mechanism, which allows the model to focus on specific parts of the input sequence while processing it. Traditionally, attention mechanisms have relied on positional encodings to provide information about the order of tokens in a sequence. However, a newer technique called Attention with Linear Biases (ALiBi) is changing the game by revolutionizing how positional information is incorporated into the model.
In this blog post, we’ll dive into the mathematical intricacies of positional encoding-based attention and compare it to the ALiBi attention mechanism. We’ll also explore the limitations of conventional positional encoding methods and highlight the advantages that ALiBi brings to the table.
Positional Encoding-based Attention

In traditional transformer models, such as the original one proposed by Vaswani et al., positional encodings are added to word embeddings to inform the model about the positions of tokens in a sequence. These encodings are often represented by sinusoidal functions.
Mathematically, the positional encoding PE(pos, i) for a token at position pos and dimension i can be expressed as:
PE(pos, i) = sin(pos / 10000^(2i/d_model))
Here, d_model represents the dimensionality of the model’s embeddings. The idea behind this encoding is to create unique representations for each position in the sequence based on the sine and cosine functions, allowing the model to distinguish between tokens based on their positions.
Drawbacks of Positional Encoding
While positional encodings have been effective for many NLP tasks, they have limitations, especially when it comes to handling longer sequences. Here are some of the drawbacks:
Limited Context
Traditional positional encodings provide a fixed pattern of positional information. This means that the model’s ability to capture long-range dependencies in sequences is limited. When processing very long sequences, the model may struggle to understand the relationships between tokens that are far apart.
Fixed Patterns
Positional encodings follow fixed mathematical patterns, such as sinusoidal waves. These patterns do not adapt to the specific context or data, potentially causing the model to generalize poorly to different sequence lengths or patterns.
ALiBi: Attention with Linear Biases
To address the limitations of traditional positional encodings, the Attention with Linear Biases (ALiBi) method was introduced. ALiBi takes a unique approach to encoding positional information within the attention mechanism.
Mathematical Expression
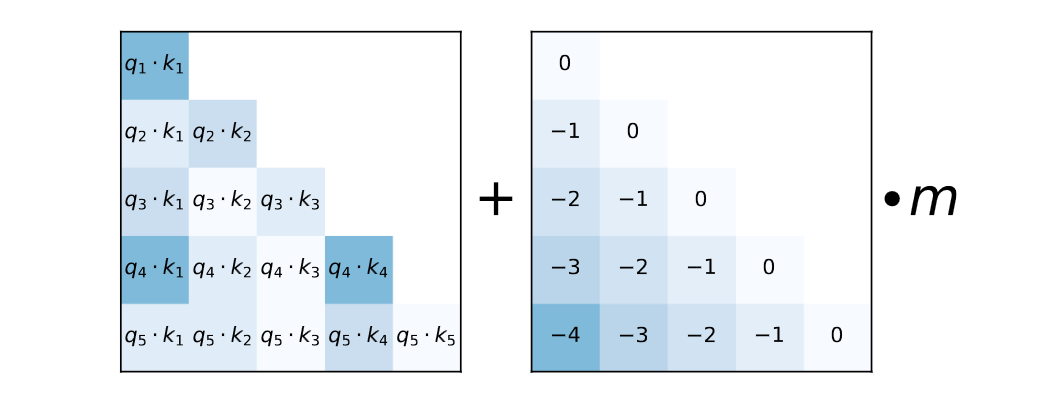
ALiBi introduces penalties in the form of linear biases that are added to the dot products between query and key vectors during self-attention. These penalties are based on a head-specific slope m and the relative positions of the query and key.
Mathematically, the penalty Penalty(i, j) for the interaction between the query at position i and the key at position j is calculated as follows:
Penalty(i, j) = m * [-(i - 1), -(i - 2), …, -2, -1, 0]
Here’s a breakdown of what this mathematical expression means:
-
Penalty(i, j) represents the bias introduced for the interaction between the query at position i and the key at position j.
-
m is a head-specific slope that determines the magnitude of the penalty. Different heads in the model may have their own slopes. In the original approach, for models with 8 heads, the slopes used are arranged in a geometric sequence: 1/2, 1/4, 1/8, and so on, up to 1/256. For models requiring 16 heads, these 8 slopes are interpolated to create another geometric sequence starting at √(1/2) and continuing with a ratio of √(1/2). The choice of slopes is important for ALiBi’s effectiveness. In general, for k heads, our set of slopes is the geometric sequence that starts at 2^(-8/k) and uses that same value as its ratio.
-
[-(i - 1), -(i - 2), …, -2, -1, 0] is a sequence of integers that represent the relative positions of the key with respect to the query. This sequence introduces a linear increase in penalties as the distance between the query and key positions increases.
Advantages of ALiBi
-
Facilitating Long-Range Dependencies: Traditional transformer models rely on positional embeddings to provide information about the position of tokens in a sequence. While these embeddings work well for relatively short sequences, they become less effective as sequences grow longer. In longer sequences, it becomes challenging for the model to capture long-range dependencies and understand the relationships between tokens that are far apart.
-
Penalizing Distant Relationships: ALiBi introduces biases in the form of penalties that are added to the attention scores during the self-attention mechanism. These penalties increase with the distance between the query and key positions. In other words, when a query attends to tokens that are far away in the sequence, the associated penalties become significant.
-
Bias Towards Recent Information: The introduced penalties effectively bias the model towards paying more attention to recent or nearby positions in the sequence while reducing the attention to distant positions. This bias reflects a preference for more recent positional information, as recent positions receive lower penalties.
-
Enhancing Generalization: By favoring recent information, ALiBi helps the model generalize better to longer sequences during both training and inference. The model learns to focus on relevant tokens within its context window, effectively ignoring irrelevant tokens in very long sequences. This selective attention mechanism enhances the model’s ability to maintain meaningful relationships and dependencies in longer contexts.
-
Efficient Extrapolation: The dynamic biasing introduced by ALiBi allows the model to extrapolate its understanding of token relationships to longer sequences. It achieves this without relying on traditional positional embeddings, which can become computationally expensive for very long sequences. ALiBi’s approach is computationally efficient and enables the model to adapt to various sequence lengths without the need for retraining.
-
Improved Performance: The bias towards recent information and the ability to extrapolate effectively result in improved model performance on longer sequences. It allows the model to handle input sequences that are significantly longer than those it was trained on while maintaining meaningful predictions and relationships between tokens.
In summary, adding bias to the attention scores in ALiBi enables efficient extrapolation to longer sequences by introducing a dynamic positional bias that favors recent information and reduces the impact of distant tokens. This bias enhances the model’s generalization and performance on longer sequences without the need for additional computational overhead, making it a valuable technique for handling sequences of varying lengths in transformer models.
Conclusion
ALiBi is a new technique that helps language models understand longer pieces of text better. It’s like a cool innovation in the world of language processing.
Researchers are always working on making these models smarter. With ALiBi, we’re getting closer to making models that can handle really long and complicated texts.
This means that in the future, we can expect even better language models that understand and work with really long pieces of writing. So, the journey of improving language technology is still going strong, and ALiBi is a big step forward in that journey.
Reference
https://arxiv.org/pdf/2108.12409.pdf