
Efficient Book Summarization using Large Language Models

In the realm of summarizing entire books using Large Language Models (LLMs), the challenge of context length emerges as a prominent hurdle. These models, while powerful, are constrained by their capacity to handle only a certain amount of text at a time. Given the extensive nature of books, accommodating the entire context within the model’s limitations becomes a formidable task.
Addressing this challenge involves relying on techniques that effectively reduce the context size without compromising the essence of the book. The art of summarization, in this context, becomes a delicate balance between distillation and retention, requiring strategies that make the most out of the available context space.
In the upcoming discussion, I will explain two techniques for summarizing large books. The first technique involves a recursive approach, mirroring a human reading process. The model is tasked with sequentially reading through the book page by page. As it progresses, it stores the previously generated summary in a memory block, conditioning its understanding of the current page on the accumulated summary. This recursive process continues until the model reaches the last page, at which point it outputs the comprehensive summary of the entire book. Despite its alignment with a human reading strategy, this approach can be time-consuming, particularly for books spanning hundreds of pages.
The second technique introduces a pragmatic solution to the time challenge by combining extractive and abstractive summarization. Initially, an extractive summarization process is employed to identify and pull key information from the text. Subsequently, this extractive summary becomes the input for the LLM, enabling it to generate a coherent and well-written abstractive summary. This two-step approach aims to strike a balance between efficiency and comprehensiveness, leveraging the strengths of each summarization method.
Recursive Approach
I will be using Llama-2 prompt for this and the process majorly depends upon the way of writing the prompt for this. Here’s a example prompt what I thought of:
PROMPT_TEMPLATE = """[INST] <<SYS>>
Below is an instruction that describes a task.
Write a response that appropriately completes the request.
<</SYS>>
You are given a summary of the book before the current page as follows:
{previous_sum}
The current page content is as follows:
{current_page}.
Now, generate a combined summary such that it contains the
key information from previous summary and current page combined.
If the previous summary is empty, consider the current page as
the first page of the book. [/INST] """
The template includes placeholders {previous_sum} and {current_page} to dynamically insert the summary of the book before the current page and the content of the current page, respectively. The instructions guide the model to generate a combined summary considering both the previous summary and the current page, with a special case handling for the first page if the previous summary is empty. You can customise the prompt accordingly varying upon your needs.
Now, let’s assume you have already processed a book pages in the form of a list, here’s how you can get the overall summary:
def summarize_page(model_endpoint, previous_sum, current_page):
query = PROMPT_TEMPLATE.format(previous_sum=previous_sum,
current_page=current_page)
data = {"query": query}
response = requests.post(model_endpoint, json=data)
response = eval(response.text)
return response
prev_sum = ""
for i in range(len(pdf_reader.pages)):
prev_sum = summarize_page(llama_enpoint, prev_sum,
pdf_reader.pages[i].extract_text())
final_summary = prev_sum
print(final_summary)
I am using a llama endpoint for generation which was served already. If you wish to know how it was done, you can refer to my previous blog. In this example, the prev_sum variable acts like a memory holder for the previous pages. You can also control the length of the previous summaries dynamically by passing a linearly increasing function for max_new_tokens for every next iteration to minimise the information loss as the number of pages increases.
Extractive Summarization Approach
Now, let’s talk about the second approach. Before I delve into the implementations, let me briefly explain what extractive summarization means and how it works.
What is Extractive Summarization?
Extractive summarization is a text summarization technique that involves identifying and extracting key sentences or phrases directly from the original text to form a condensed version. Unlike abstractive summarization, which involves generating new sentences to convey the essential information, extractive summarization relies on selecting existing content. The goal is to retain the most informative and relevant segments of the text, often determined by factors such as sentence importance, coherence, and overall significance.
Now performing an extracive summarization typically involves the following steps:
TextRank Based Approach
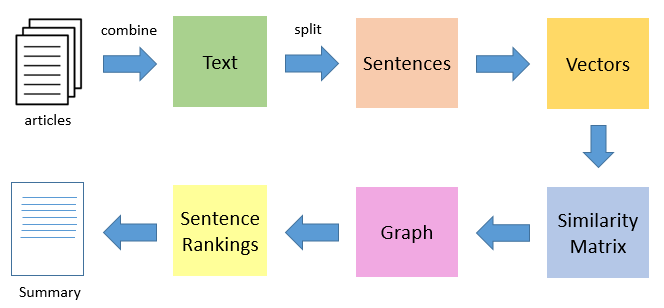
- Create chunks of the original document
- Compute vector representations for those chunks
- Rank the chunks according to their relevance
- Pick the top k chunks and represent them in the order they appear in the original document
Clustering Based Approach
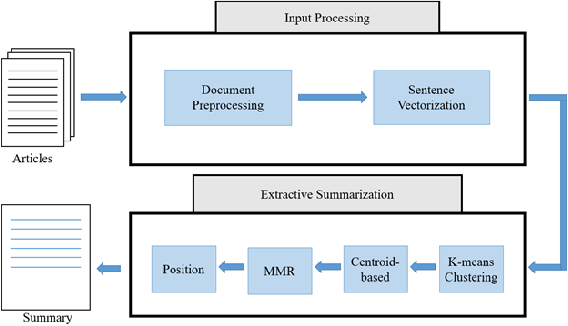
- Create chunks of the original document
- Compute vector representations for those chunks
- Perform a clustering operation for the chunk vectors and find K centroids
- Find K chunks(each from the cluster) closest to their respective centroids
- Contatenate them together in the order they appear in the original document
You can choose to perform any of the two approaches(or some other methods) to generate the extractive summary of the entire book. Generating the extractive summary hugely decreases the context length eliminating repeatitive chunks/less relevant chunks from the original document, thus making it easier for us to pass the extracted information entirely to the LLM. Now, let’s dive into the coding part and see how it can be done. I will be using a bert-extractive-summarizer library for the extractive summarization. It is a clustering based approach after vectorizing the chunks using a BERT styled encoder.
from summarizer import Summarizer
text = ""
for page in pdf_reader.pages:
text += page.extract_text() + "\n\n"
extractive_summary = extractive_summarization(text, ratio=0.2)
PROMPT_TEMPLATE = """[INST] <<SYS>>
Below is an instruction that describes a task.
Write a response that appropriately completes the request.
<</SYS>>
You are given a extractive summary of a book as follows:
{extractive_summary}
Now, generate a well-written summary such that it describes
the contents of the book in a coherent manner.
Try to be as descriptive as possible.[/INST] """
query = PROMPT_TEMPLATE.format(extractive_summary=extractive_summary)
data = {"query": query, "tokens": 700}
response = requests.post(model, json=data)
summary = eval(response.text)
print(response)
Combined Approach
The recursive approach, while mirroring a human reading process, encounters a significant drawback when dealing with extensive books or documents. As the number of pages increases, there is a heightened risk of losing crucial information from the initial pages. The model’s reliance on storing summaries in a memory block introduces a potential limitation, with the accumulating summaries becoming more susceptible to information degradation over an extended reading span. This drawback is particularly pronounced in the context of lengthy books, where the sheer volume of information can overwhelm the model’s ability to retain and consolidate key insights from the entire document.
On the other hand, extractive summarization has its own set of limitations. The approach may result in missing essential information since it selects only one chunk from each cluster of related content. Additionally, the rigid nature of extractive summarization, where chunks are chosen based on predetermined criteria, forces the user to set a ratio for length control. If the document is substantial and the ratio is set too conservatively, there’s a risk of losing critical details. This trade-off between length control and information retention presents a challenge, especially when dealing with large and diverse textual datasets. In light of these considerations, a hybrid approach that combines elements of both recursive and extractive summarization emerges as a more balanced strategy, allowing for comprehensive coverage while addressing the limitations of individual methods.
Let’s see how we can do this.
While the diagram above should be self explanatory, let me go through the steps:
- We first split the book chapterwise
- Then extractive summaries for each chapter is generated
- Then, we generate abstractive summaries from each of the extractive summaries in the previous step
- At last we are left with a condensed form of the book and can levarage the recursive approach which minimises the information loss and generate the final summary of the book.
Conclusion
By leveraging extractive summarization to distill key information efficiently and employing recursive techniques to maintain context and coherence, a hybrid approach can strike a balance between comprehensiveness and efficiency. As technology continues to evolve, refining these methods and exploring innovative strategies will undoubtedly enhance our ability to distill the essence of lengthy texts, making the world of information more accessible and manageable.
References
- https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
- https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
- https://arxiv.org/pdf/1906.04165.pdf