
Working with Generative Language Models
- So, what are LLMs?
- What makes ChatGPT different from other LLMs like GPT, GPT2, GPT3, Bloom etc?
- How to use RLHF with PPO for improving an LLM?
- Proximal Policy Optimization
- Challenges
- Instruction Based Fine Tuning
- Dolly by Databricks
- Conclusion
- References

This extensive article will discuss the current trending technology in the Machine Learning space, namely ChatGPT and other Large Language Models (LLMs). With the introduction of ChatGPT by OpenAI, an LLM that is being touted as the initial step towards Artificial General Intelligence, the tech industry is in a state of amazement. ChatGPT is an AI that can converse like humans, possesses general intelligence to comprehend any instructions provided to it, and has the potential to replace humans in various jobs within the tech industry. A few years back, Google published a research paper titled “Attention is all you need,” which has now become the basis for this innovative technology that has created a lot of hype in the tech industry. This article aims to define terms such as Transformers, LLMs, CLMs, ChatGPT, and other open-source LLMs.
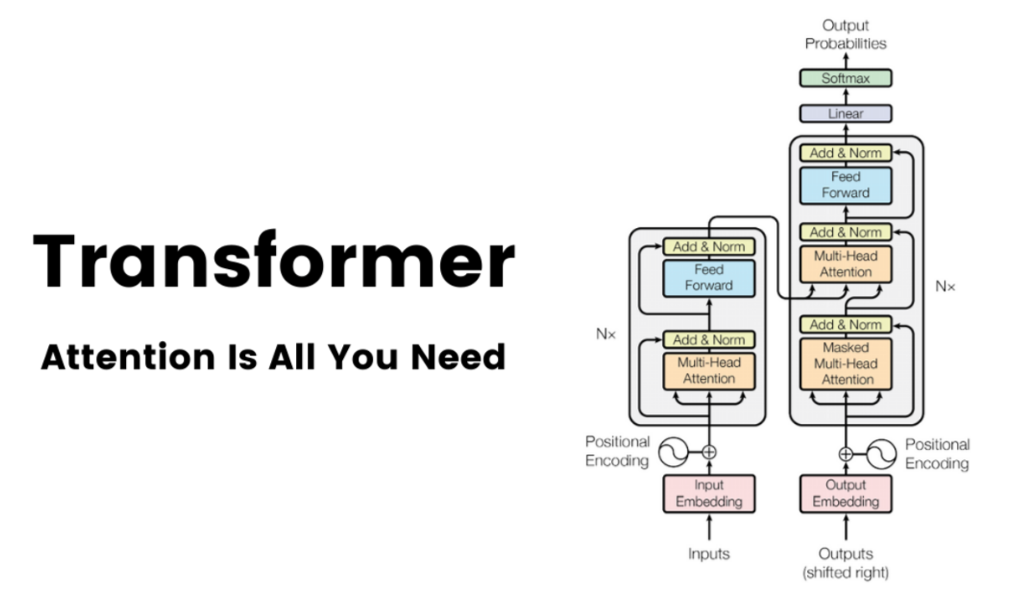
So, what are LLMs?
LLM stands for Large Language Model. An LLM is an advanced type of artificial intelligence model that uses deep learning techniques to analyze and understand large amounts of natural language data. These models are trained on massive datasets, such as books, websites, and social media platforms, to learn the patterns and structures of language. Once trained, LLMs can perform a wide range of natural language tasks, such as text generation, question-answering, language translation, and text summarization. ChatGPT is an example of an LLM that has garnered significant attention in recent years for its impressive language abilities.
You must have heard of Transformers even before the product ChatGPT came into picture. Now, let us talk about the main two types of transformers:
- Transformers trained on the objective of MLM and NSP
- Transformers trained on the objective of CLM
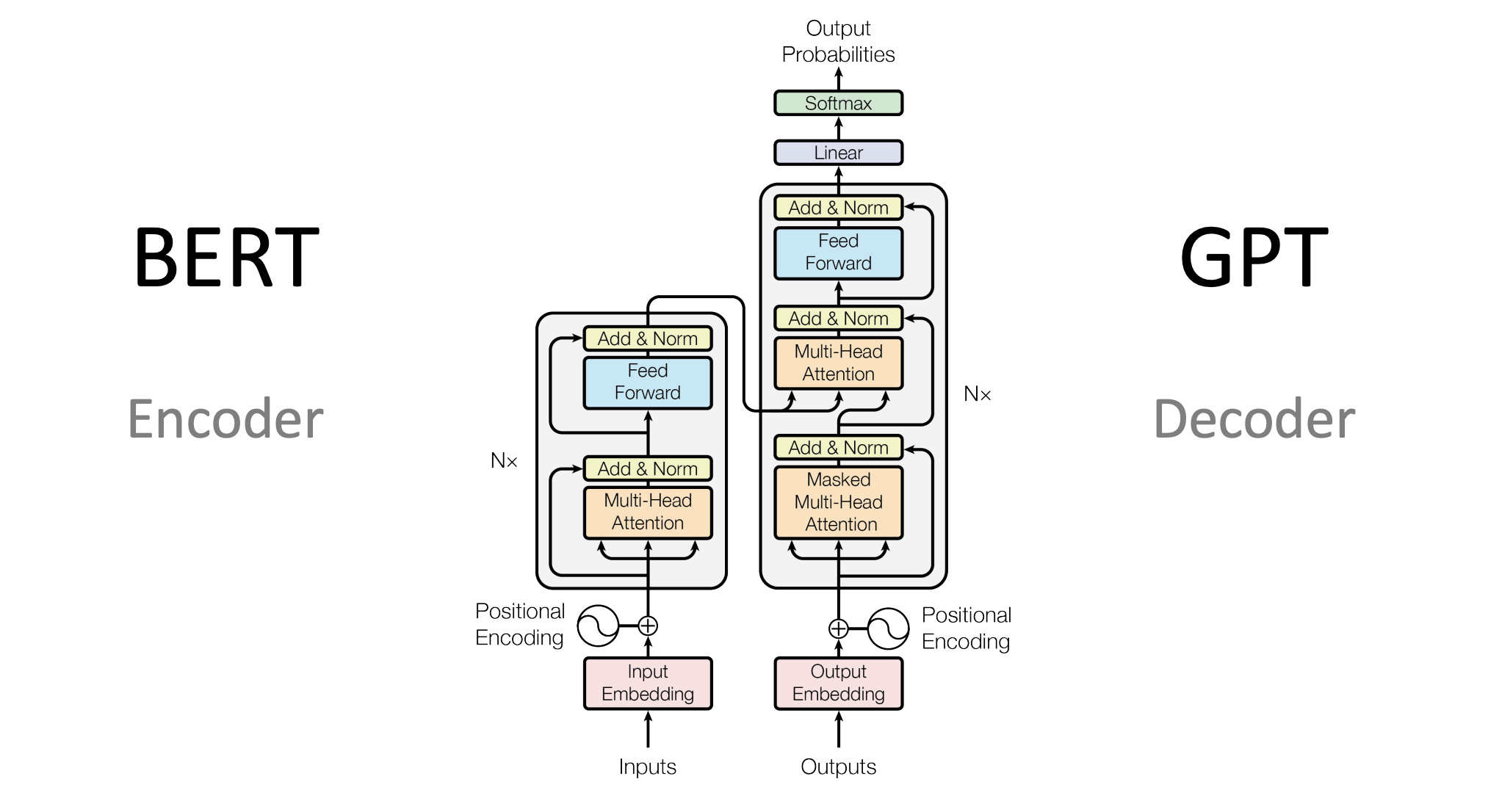
Transformers are trained on different objectives to perform various natural language processing tasks. Two main types of transformers exist based on their training objectives. The first type is trained on the objective of MLM (Masked Language Model) and NSP (Next Sentence Prediction). These models are trained to predict a missing word in a sentence (MLM) and determine whether two sentences are consecutive (NSP). The MLM objective helps the transformer understand the context of a sentence by predicting what word might be missing from a given sentence, and the NSP objective helps the transformer understand the relationship between sentences in a document or paragraph. BERT is the most popular example of this type of models. These models are intended to represent the text into a numerical space vector with its semantic meaning embedded to it.
The second type of transformer is trained on the objective of CLM (Causal Language Modeling). These models generate text by predicting the next word in a sequence based on the previous words. Unlike bidirectional models that use both past and future context to make predictions, CLMs only use past context. This makes them ideal for tasks such as text generation, summarization, and speech recognition. The most popular example for these kind of models is GPT which is intended to generate the next possible word, given a prior context. ChatGPT is one such CLM(a decoder based Transformer). These models are very large in terms of number of parameters(in billions) as compared to the encoder based Transformers like BERT(in millions).
What makes ChatGPT different from other LLMs like GPT, GPT2, GPT3, Bloom etc?
Answer: RLHF(Reinforcement Learning based on Human Feedback)

Reinforcement Learning Based on Human Feedback (RLHF) is a type of machine learning that incorporates human feedback into the learning process. Traditional reinforcement learning involves an agent taking actions in an environment and receiving rewards or punishments based on its actions. RLHF extends this approach by allowing humans to provide feedback to the agent in the form of rewards or penalties, rather than relying solely on pre-defined reward functions. This approach is particularly useful in situations where the reward function is difficult to specify or where the consequences of actions are not immediately clear.
In recent years, language models have made remarkable progress in generating compelling and diverse text in response to human input prompts. However, the definition of a “good” text is elusive, as it is dependent on context and subjectivity. For instance, creative writing requires ingenuity, informative text necessitates factual accuracy, and code snippets must be executable. Developing a loss function that accounts for all these attributes is an arduous task, and most language models continue to be trained using a basic next token prediction loss such as cross-entropy.
To overcome this challenge, researchers have proposed metrics like BLEU or ROUGE that are better suited to capture human preferences than the loss function. These metrics, however, have their own limitations as they merely compare generated text to references using simple rules. Imagine being able to use human feedback to evaluate generated text performance or even use it as a loss function to optimize the model. This is the idea behind Reinforcement Learning from Human Feedback (RLHF), which leverages reinforcement learning methods to optimize language models with human feedback. RLHF enables language models to align with complex human values rather than simply being trained on a generic corpus of text data.
How to use RLHF with PPO for improving an LLM?
Let us take an example of a text-summarization task for reddit posts. RLHF involves a policy function and a reward model. The task of policy function is to generate text given a prompt and reward model’s job is to evaluate the response(like a human would do) and output a score(reward/penalty). The score is used further to update the policy function(LLM in this case) using a reinforcement learning algorithm called PPO. Let’s briefly talk about what PPO is.
Proximal Policy Optimization
The Proximal Policy Optimization (PPO) algorithm is a popular reinforcement learning technique used for training agents to perform tasks in complex environments. PPO belongs to the family of policy gradient methods that optimize the policy of an agent to maximize the cumulative reward obtained over a series of interactions with the environment. PPO uses a clipped surrogate objective function to prevent large policy updates, which can destabilize training. This ensures that the new policy is not too far from the old policy, and thus the agent’s behavior does not change abruptly.
The PPO algorithm has several advantages over other policy gradient methods, including high sample efficiency, good scalability to large-scale problems, and stable convergence properties. It has been successfully applied to a wide range of tasks, such as robotics control, game playing, and natural language processing. PPO has proven to be a powerful tool for training reinforcement learning agents.
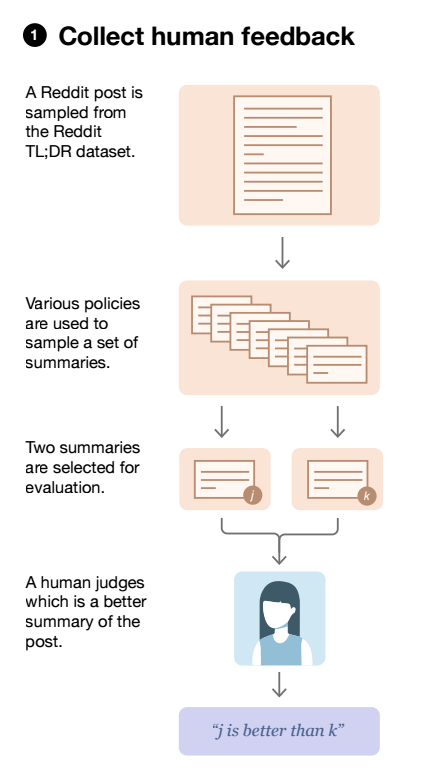
To train an LLM using RLHF, you need to have a very accurate reward model which can mimic humans in evaluating the responses. OpenAI invested a lot of money in collecting a large number of human annotated data points which were used to train a reward model.
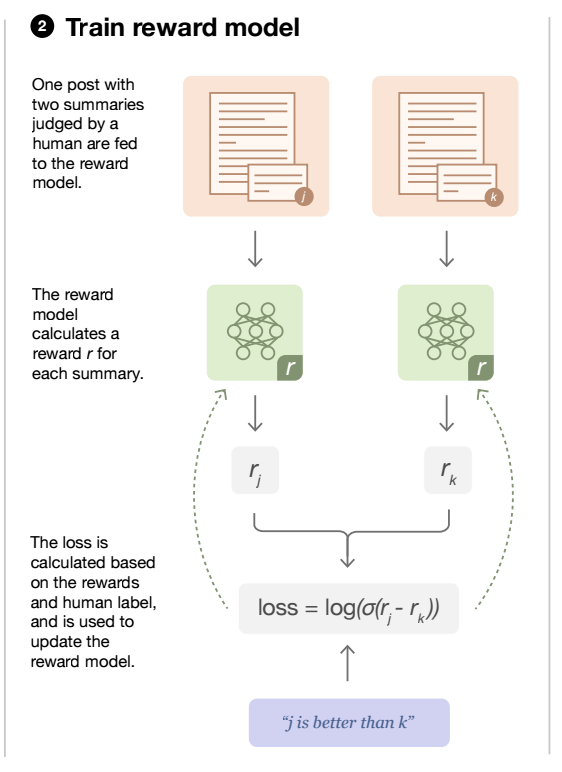
While it is a very expensive process, you can still use a reward function based on custom strategies for a limited number of tasks. For eg., a cross encoder to find the correlation between the expected response and the actual response given by the LLM.
Now, let us assume you have a reward model ready. We can use it train the policy function which is the LLM in this case as shown in the image below:
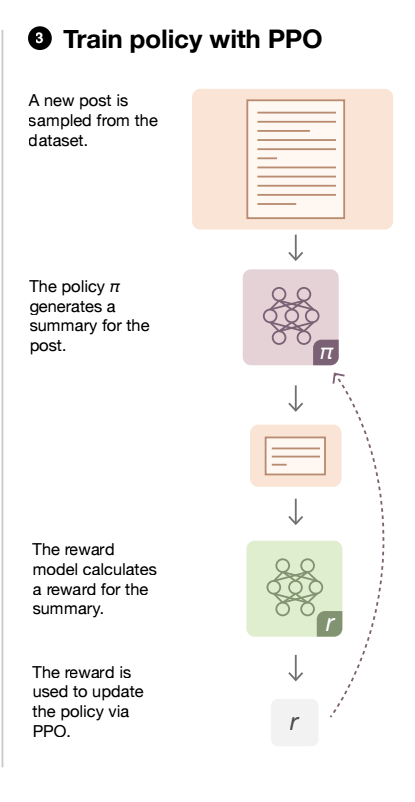
Challenges
There are several challenges associated with using Reinforcement Learning based on Human Feedback (RLHF) for training Large Language Models (LLMs). One major challenge is obtaining high-quality human feedback consistently. Human feedback can be noisy, subjective, and time-consuming to obtain, and it can vary widely across individuals. This means that the RLHF algorithm must be robust enough to handle such variations and able to differentiate between good and bad feedback. Moreover, the algorithm must be able to learn from feedback that is not always explicit or quantitative, such as implicit feedback through user behavior or reactions.
Another challenge is the scalability of RLHF for LLM training. LLMs require a large amount of training data and computing resources, and RLHF can significantly increase the amount of human involvement required for training. This can result in significant time and resource costs, which may not be feasible for many organizations. Additionally, RLHF requires a feedback mechanism that is integrated into the LLM training process, which may require significant changes to existing infrastructure and workflows. Therefore, it is important to carefully consider the costs and benefits of RLHF for LLM training before adopting it.
Instruction Based Fine Tuning
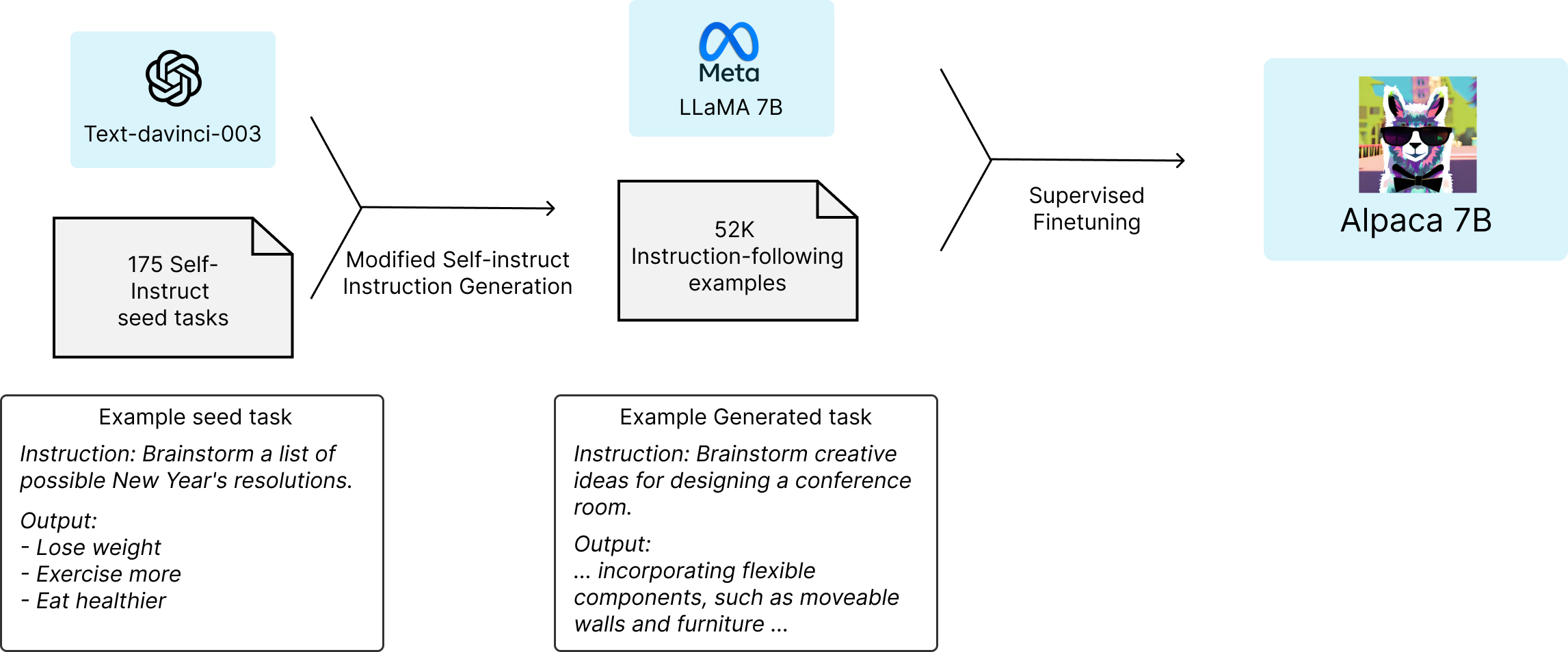
Stanford University has released its new open-source instruction-following language model called Alpaca, which is designed to address the shortcomings of existing instruction-following models. The Alpaca model is fine-tuned from Meta’s LLaMA 7B model and trained on 52,000 instruction-following demonstrations generated in the style of self-instruct using text-davinci-003.
The increasing popularity of instruction-following models such as GPT-3.5 (text-davinci-003), ChatGPT, Claude, and Bing Chat has led to their widespread deployment, but they still have several deficiencies. They can generate false information, propagate social stereotypes, and produce toxic language. Stanford’s Alpaca model is designed to mitigate these issues and enable the academic community to engage in research on instruction-following models more easily.
Alpaca is intended only for academic research, and commercial use is prohibited. The instruction data used to train the model is based on OpenAI’s text-davinci-003, whose terms of use prohibit developing models that compete with OpenAI. Additionally, Alpaca is not ready to be deployed for general use as the safety measures are not yet adequate.
To address the challenge of training a high-quality instruction-following model under an academic budget, two important factors are required: a strong pretrained language model and high-quality instruction-following data. The Alpaca model uses Meta’s LLaMA models to address the first challenge, while the self-instruct method is used to generate high-quality instruction data. The data generation process resulted in 52K unique instructions and corresponding outputs at a cost of less than $500 using the OpenAI API.
The Alpaca model shows many behaviors similar to OpenAI’s text-davinci-003 but is surprisingly small and easy/cheap to reproduce. Stanford has released the training recipe and data, and an interactive demo to enable the research community to better understand the behavior of Alpaca. The community is encouraged to report any concerning behaviors in the web demo so that Stanford can better understand and mitigate these behaviors.
Stanford Alpaca is a promising language model developed by researchers at Stanford University. However, it should be noted that the model uses a non-commercial language model called LLAMA, which may limit its commercial potential. Additionally, the dataset used to train Stanford Alpaca is generated by OpenAI API, which contains restrictions preventing the creation of a model that directly competes with OpenAI. This means that the model cannot be used by enterprises for commercial purposes. Despite these limitations, Stanford Alpaca is still a useful tool for academic and research purposes and has the potential to contribute to advancements in natural language processing.
Dolly by Databricks
![]()
The team at Databricks has developed a new model called Dolly that democratizes instruction-following LLMs, making them accessible to companies of all sizes. Unlike ChatGPT, Dolly is an open source model that anyone can create using high-quality training data and just 30 minutes of training time on a single machine. Despite being based on an older architecture and having only 6 billion parameters (compared to ChatGPT’s 175 billion), Dolly exhibits many of the same qualitative instruction-following capabilities, including text generation, brainstorming, and open Q&A.
Dolly works by taking an existing open source LLM from EleutherAI and modifying it slightly with data from the Alpaca model, which was based on LLaMA but fine-tuned on a small dataset of human-like questions and answers. The result is a clone of the Alpaca model that exhibits ChatGPT-like interactivity and instruction-following capabilities. One of the most exciting things about Dolly is that it shows how much of the gains in state-of-the-art models like ChatGPT may be due to focused corpuses of instruction-following training data rather than larger or better-tuned base models. This means that companies can build their own high-quality instruction-following models without having to invest in massive amounts of computing power or expensive proprietary software.
To create your own Dolly model, all you need is high-quality training data and access to Databricks. The team has open-sourced the code for Dolly and provided instructions for how to recreate the model on their platform. With this new technology, companies of all sizes can now take advantage of the power of instruction-following LLMs to improve their products and services.
We’re still in the earliest days of the democratization of AI for the enterprise, and there is much work to be done. However, Dolly represents an exciting new opportunity for companies that want to cheaply build their own instruction-following models. With this technology, the possibilities are endless.
Dolly, a large language model developed by Databricks, was trained by fine-tuning GPT-J. However, the dataset used for Dolly’s training, Alpaca, is not commercially licensed, and therefore Dolly cannot be used for commercial purposes. To address this limitation, Databricks created its own dataset consisting of 15k instruction/response pairs. This dataset was built collaboratively by 5000 employees at the company. The dataset is open-source and can be used for any purpose, including commercial tasks. Although the quality of this dataset may not be the best, it shows a promising start for many tasks. Moreover, enterprises and teams can build their own custom dataset and train a large language model that aligns with their specific needs. The creation of custom datasets helps in improving the model’s accuracy in specific domains or tasks. Databricks’ custom dataset creation for LLM GPT-J training is a testament to the growing need for open-source datasets that can be used for commercial purposes. The collaboration of 5000 employees to build the dataset highlights the power of collective efforts in the field of AI. It is also an example of how companies are taking ownership of their data and using it to create custom solutions to meet their specific needs.
Conclusion
In conclusion, while Dolly cannot be used for commercial purposes due to the limitations of the Alpaca dataset, Databricks’ custom dataset creation provides a promising solution for training LLM GPT-J models that can be used for commercial tasks. The ability to build custom datasets and train models that align with specific needs is a powerful tool in the field of natural language processing, and we can expect to see more companies following Databricks’ lead in the future. While this is not the end of the AI revolution, infact it’s just getting started. The sheer pace of development in this field is phenomenal. The contents of this blog can already be outdated in a few days considering the fast paced progress. In the next blog, I will be demonstrating on how to train your own Dolly.
Until then, Keep Learning, Keep Sharing 🙂
References
1) https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
2) https://crfm.stanford.edu/2023/03/13/alpaca.html
3) https://huggingface.co/blog/rlhf