
How to Make Your Agents Dream
Modern AI agents are getting very good at acting. They can call tools, read documents, query databases, search vector stores, write code, update records, and coordinate multi-step workflows. In other words, they are becoming useful not because they can answer questions in isolation, but because they can participate in real systems.
But action is only half of intelligence. The other half is learning from experience.
Humans rarely improve only in the moment of doing a task. We improve afterward, when we replay what happened, notice patterns, compress messy details into lessons, forget what was irrelevant, and reconcile what contradicted our previous understanding. Sleep and dreaming are part of that biological process, but the metaphor is useful even outside biology. A system that only acts and never consolidates its experience is condemned to repeat itself.
Agents need a version of this.
Not literal dreams, of course. What they need is an offline process that reviews completed work, studies traces and outcomes, identifies what changed, and updates future behavior only when the lesson is grounded, scoped, and validated. I like to think of this as agent dreaming: the background consolidation loop that turns raw experience into reliable memory.
The Problem With Naive Agent Memory
The simplest way to give an agent memory is to append a new note after every interaction. If a user corrects the agent, save the correction. If a tool call fails, save the failure. If a workflow succeeds, save the strategy. Over time, the agent accumulates a long list of lessons that can be retrieved during future runs.
At first, this sounds reasonable. It is also dangerously incomplete.
A memory system that appends every lesson will eventually grow without control. Retrieval becomes noisy because too many similar memories compete for attention. Old lessons stay active after APIs, schemas, tools, or policies have changed. A memory that was valid for one workflow gets applied to another. A one-time user correction becomes a global rule. Contradictory memories accumulate, and the agent becomes less stable rather than more intelligent.
The deeper problem is that raw experience is not the same thing as wisdom. A single trace may be misleading. A user correction may apply only to one case. A failed run may have been caused by a temporary outage rather than a bad strategy. If every interaction can directly update active guidance, then the agent is not learning carefully. It is letting the last event rewrite its future behavior.
That is why production-grade agent memory should not behave like an append-only notebook. It should behave more like a governed datastore with evidence, lifecycle state, validation, and rollback.
Two Speeds of Learning
A safer design separates memory into two speeds.
The first speed is fast evidence capture. When an agent finishes a workflow, the system records what happened. It captures observability traces, tool calls, retrieved context, eval results, user feedback, latency, cost, errors, and workflow metadata. This becomes episode memory: a durable record of experience.
Episode memory is important, but it should not automatically become future guidance. It is evidence, not instruction. It says, “This happened,” not “Always do this next time.”
The second speed is slower consolidation. In the background, the system periodically reviews accumulated episodes, searches for related patterns, identifies stale or contradictory guidance, generates candidate replacements, evaluates them, and only then promotes selected lessons into active memory.
That slower process is the agent’s dream cycle.
This distinction matters because learning should not block the user-facing workflow, and it should not be driven by a single moment of feedback. The active workflow should finish quickly and leave behind enough evidence for later analysis. The memory system can then take its time, compare many episodes, check whether a lesson generalizes, and decide whether anything should actually change.
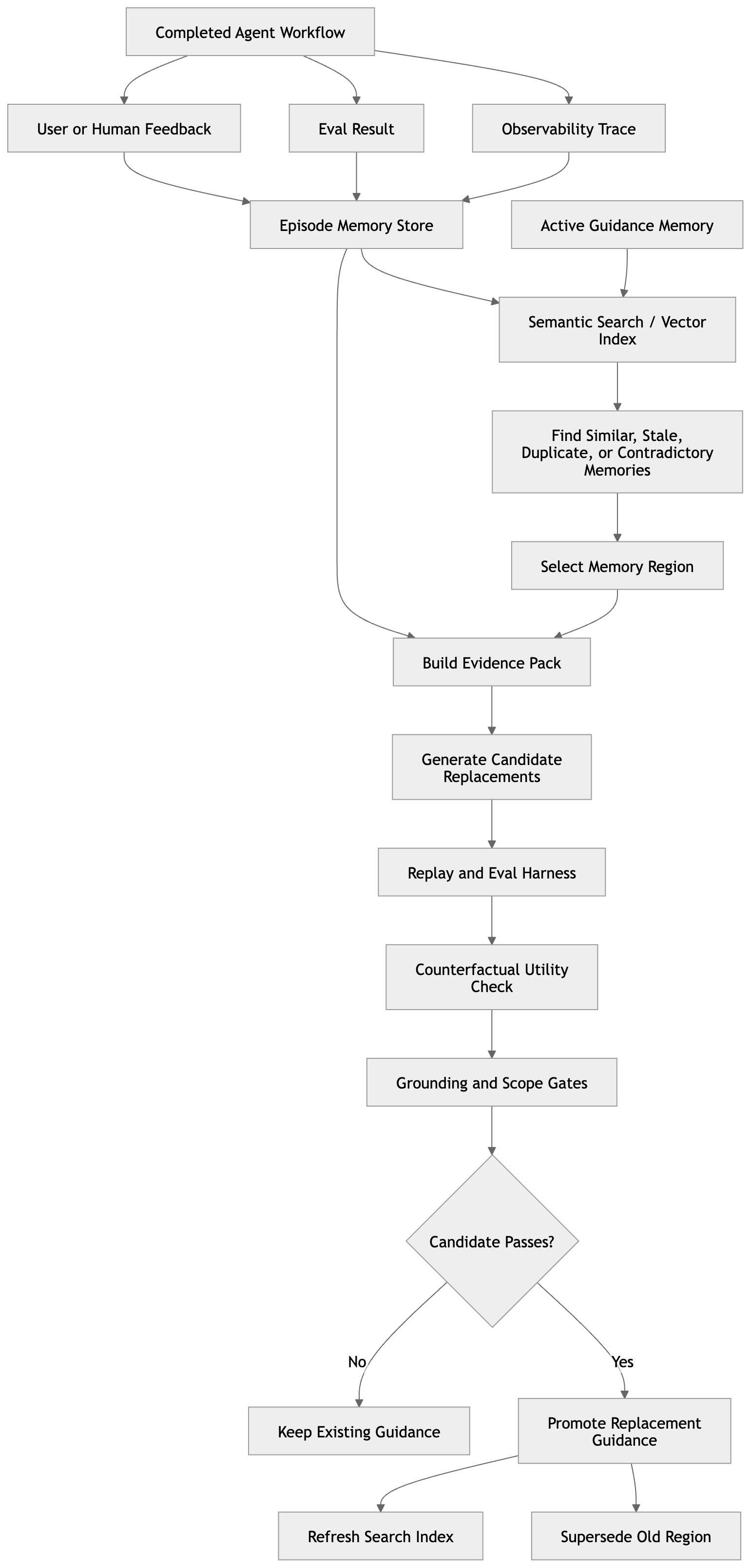
What Happens During an Agent Dream?
An agent dream is not just a prompt that says, “Summarize what we learned today.” That would create another unverified model output and call it memory. A useful dream cycle is more structured.
It begins by selecting a bounded region of memory to review. That region might be related to a workflow, a tool, a datastore, a user journey, a failure pattern, or a semantic topic. The key is that the system does not try to rewrite all memory at once. It chooses a working area where there is enough evidence to justify consolidation.
Next, the system builds an evidence pack. This pack includes the existing guidance, related successful runs, related failed runs, human corrections, eval scores, tool outputs, and any relevant metadata such as tool versions or schema versions. The evidence pack should be bounded and provenance-linked. The consolidation process should know exactly what evidence it is allowed to use and what memory region it is allowed to replace.
An LLM or agentic process can then generate candidate replacement memories. One candidate might be conservative, preserving most of the current guidance while removing obvious stale details. Another might aggressively compress duplicate memories. A third might focus on resolving contradictions. A fourth might convert scattered observations into a clearer reusable procedure.
The important constraint is that the model proposes; it does not decide. Candidate memories are not activated merely because they sound plausible. They must be tested.
Memory Should Be Evaluated Like Behavior
A memory is useful only if it improves future behavior.
That may sound obvious, but many memory systems skip this step. They judge memories by readability, not utility. A memory can be well-written and still useless. It can repeat information already present in the prompt. It can be too vague to influence the agent. It can be retrieved often but ignored. It can even make the agent worse by biasing it toward an outdated strategy.
This is where replay and evals become essential. The system can compare behavior using the current memory against behavior using a candidate replacement. It can replay known workflows, check whether previous failures are reduced, verify that successful workflows do not regress, and measure side effects such as latency or cost.
A stronger version of this is counterfactual utility testing. Remove or mask a candidate memory and measure whether anything changes. If removing it hurts performance, the memory is probably load-bearing. If removing it has no effect, the memory may be redundant. If removing it improves performance, the memory may be harmful.
This gives memory a practical test: not “does this sound insightful?” but “does this help the agent do the right thing?”
Region Replacement Is Safer Than Row Editing
Another important design choice is to avoid editing individual memory rows in place.
Instead of treating memory as a pile of independent notes, the system can treat related memories as a region. During consolidation, the selected region becomes read-only. The system studies it, gathers evidence around it, generates replacement candidates, validates them, and either accepts one replacement region or keeps the existing region unchanged.
This makes memory updates cleaner. The old region can be superseded rather than destroyed. The new region can point back to the evidence that justified it. Reviewers can inspect what changed and why. If the replacement causes regressions, rollback is possible.
Row-level editing is tempting because it feels simple. But over time, it creates invisible drift. A sentence gets changed here, another memory gets deleted there, a third memory gets merged somewhere else, and eventually nobody can explain why the agent behaves the way it does.
Region replacement gives memory the same kind of discipline we expect from production systems. We version code. We version schemas. We version models. We should also version important behavioral memory.
Why Observability Is the Foundation
Agent dreaming only works if the system has enough evidence to dream about.
If all you store is the final answer and a thumbs-down, there is very little to learn. The agent may have failed because it retrieved the wrong document, called the wrong tool, misunderstood a schema, skipped a required policy check, used stale memory, or simply had insufficient context. Those are very different lessons.
A strong observability layer captures the trace of the workflow: what the agent saw, what it retrieved, which tools it called, what those tools returned, what decisions it made, where it hesitated, and how the outcome was evaluated. This does not mean every token needs to become active memory. It means the system needs enough structured evidence to distinguish between causes.
For example, suppose an agent keeps failing when answering questions about a datastore. Without traces, the memory system might produce a vague lesson like “be careful with datastore queries.” With traces, it might discover that the agent is consistently using semantic search when it should first inspect schema metadata, or that a specific vector index is stale, or that a tool description is causing the model to choose the wrong API.
Better evidence leads to better memory.
Vector Search Is Useful After the Workflow Too
Vector databases are usually discussed as runtime retrieval systems: the agent embeds a query, retrieves relevant context, and uses that context to answer or act. But semantic search is just as valuable after the workflow is over.
During dreaming, vector search can help find similar episodes, duplicate memories, contradictory guidance, and evidence that supports or refutes a proposed update. This is especially useful because memory problems are rarely obvious from one record. Staleness often appears as a pattern across many runs. Contradiction appears when two plausible instructions point in different directions. Low utility appears when a memory is retrieved repeatedly but does not improve outcomes.
The vector database becomes a kind of associative memory for the consolidation process. It helps the system ask, “Where else have we seen something like this?” and “Does recent evidence still support this guidance?”
This also helps prevent overfitting to one event. Instead of turning a single failure into a global lesson, the system can search for related evidence and decide whether the failure was isolated, repeated, or already contradicted by successful runs.
Scope Is What Prevents Memory From Becoming Dangerous
A lesson is only safe when the system knows where it applies.
Many agent failures come from overgeneralization. A user preference from one task is applied to all tasks. A workaround for one tool version survives after the tool is fixed. A procedure for one datastore is used against another. A policy that applied in one region or tenant is treated as universal.
Every promoted memory should therefore carry scope. The scope might include workflow type, tool version, datastore, user boundary, tenant boundary, data classification, time range, confidence level, and source evidence. A memory without scope is a global instruction waiting to cause trouble.
This is one of the biggest differences between casual personalization and production memory. In a consumer chat setting, “the user likes concise answers” may be harmless. In an enterprise workflow, “use this datastore for claims lookup” or “skip this validation step” can have serious consequences if applied outside the context where it was learned.
Agent dreaming should not just produce better memories. It should produce narrower memories.
A Simple Architecture for Agent Dreaming
At a high level, the architecture has five layers.
First, the agent completes workflows and emits observability data. This includes traces, tool calls, retrieved context, eval results, feedback, and workflow metadata.
Second, the system writes episode memory. These records preserve what happened, but they are not directly used as active guidance.
Third, a search layer indexes episodes and active memories. This may include a vector database for semantic similarity, keyword search for exact matches, and structured filters for scope and metadata.
Fourth, an offline consolidation job selects a memory region, builds an evidence pack, generates replacement candidates, and evaluates them through replay, evals, utility checks, grounding checks, and scope gates.
Fifth, the memory store promotes only validated replacements into active guidance. The old region is superseded, control records capture lifecycle decisions, and the search index is refreshed.
The Agent Should Sleep on It
The phrase “agent memory” often suggests that agents should remember more. I think the better goal is that agents should remember better.
They should capture experience quickly but learn from it slowly. They should preserve raw evidence but avoid turning every event into guidance. They should use LLMs to propose memory updates but rely on evals and governance to activate them. They should retire stale lessons, merge duplicates, narrow overgeneralized rules, and preserve rollback paths.
That is what it means to make agents dream.
Not hallucination. Not imagination. Not uncontrolled self-modification.
Agent dreaming is offline memory consolidation. It is the process by which traces become episodes, episodes become evidence, evidence becomes candidate guidance, and only validated guidance becomes part of future behavior.
The agents that matter most will not be the ones that remember everything. They will be the ones that know what to forget, what to preserve, and what to sleep on.