
Paper Summaries
- LLaMA-Omni: Seamless Speech Interaction with Large Language Models
- The Perfect Blend: Redefining RLHF with Mixture of Judges
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Introduction
Imagine interacting with your favorite language model, not through typing, but through natural, flowing conversation. This is the vision driving the development of LLaMA-Omni. The paper identifies the limitations of existing LLMs, primarily restricted to text-based interactions, and proposes a novel architecture, LLaMA-Omni, to bridge this gap.
In-Depth Look at the LLaMA-Omni Model Architecture
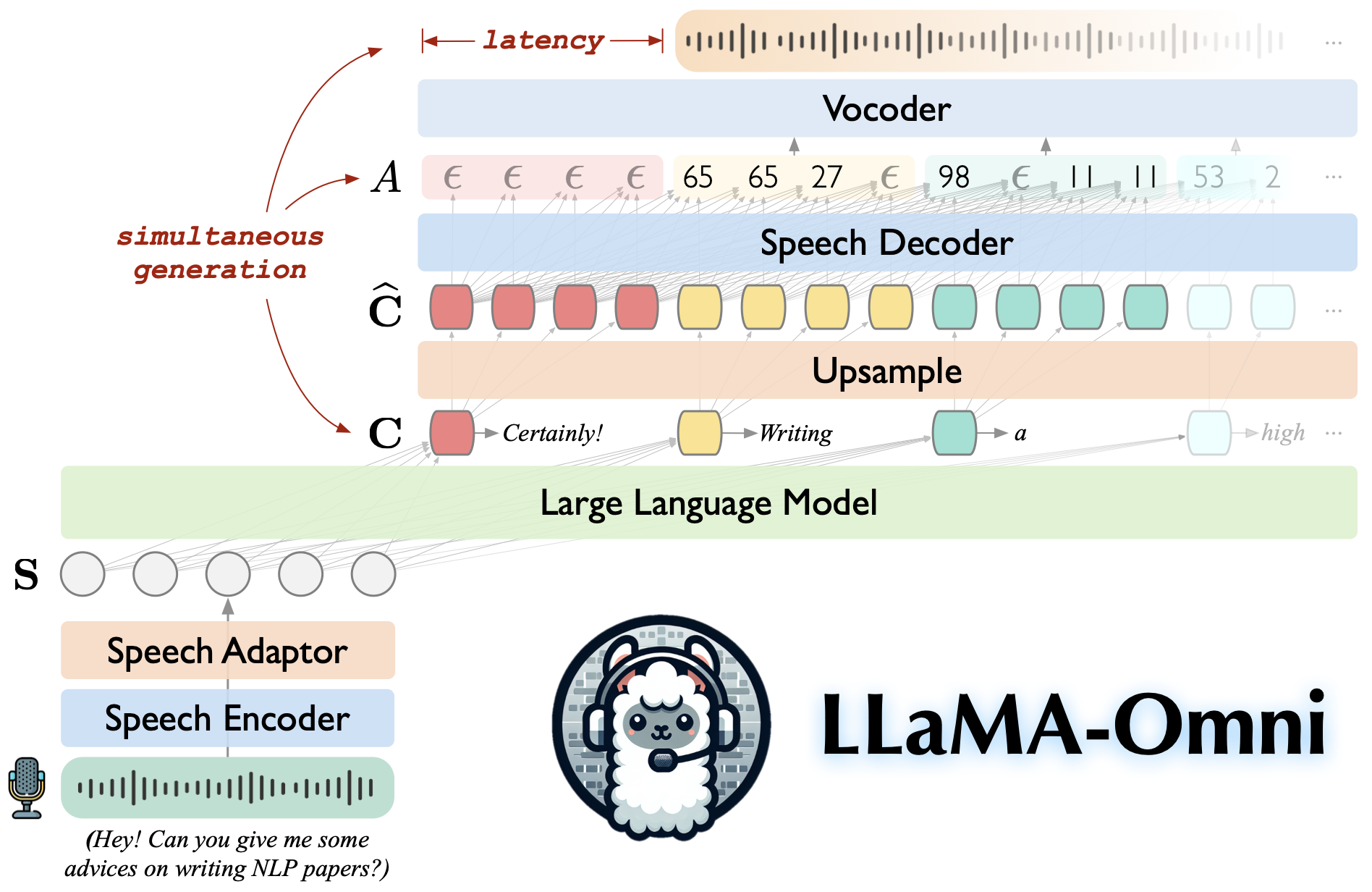
LLaMA-Omni’s architecture is carefully designed to facilitate real-time, bi-directional communication between users and LLMs. Let’s dissect each module:
1. Speech Encoder (E):
- Purpose: This module acts as the “ear” of the system, converting raw audio input (user speech) into a format understandable by the subsequent components.
- Implementation: The paper leverages the powerful encoder from Whisper-large-v3, a state-of-the-art speech recognition model trained on massive audio datasets. This choice leverages Whisper’s pre-trained ability to extract meaningful representations from speech without requiring additional training for this specific task.
- Output: The speech encoder produces a sequence of high-level speech representations, denoted as
H = [h1, ..., hv], whereNis the length of the sequence and eachhicaptures the essence of a short segment of the input audio.
2. Speech Adaptor (A):
- Purpose: Acting as a “translator”, this module bridges the gap between the speech encoder’s output format and the input format expected by the large language model.
- Implementation: The speech adaptor employs a two-step process:
- Downsampling: To reduce computational overhead, the speech representation sequence
His downsampled by concatenating everykconsecutive frames along the feature dimension. This results in a shorter sequenceH'. - Perceptron Layers: The downsampled sequence
H'is then passed through a 2-layer perceptron with ReLU activation in between. This transforms the representations into a format aligned with the LLM’s embedding space.
- Downsampling: To reduce computational overhead, the speech representation sequence
- Output: The final output of the speech adaptor is a sequence of speech representations,
S, specifically tailored for the LLM’s consumption.
3. Large Language Model (LLM) (M):
- Purpose: This is the “brain” of the system, responsible for comprehending the user’s intent (encoded within the speech representations) and generating relevant, meaningful responses.
- Implementation: The paper utilizes Llama-3.1-8B-Instruct, a powerful and publicly available LLM known for its strong reasoning capabilities and alignment with human preferences.
- Input: The LLM receives the adapted speech representations
Salong with a carefully designed prompt templateP(S)which guides the model towards generating responses suitable for speech interaction scenarios. - Output: Based on the input, the LLM generates a text response
YT = [y1, ..., yT]in an autoregressive manner, predicting one word at a time.
4. Streaming Speech Decoder (D):
- Purpose: This module serves as the “mouth” of the system, generating the final speech audio output corresponding to the text response produced by the LLM. It does so concurrently with the LLM’s text generation, enabling real-time, low-latency speech synthesis.
- Implementation: The decoder utilizes a non-autoregressive (NAR) Transformer architecture combined with connectionist temporal classification (CTC).
- Non-autoregressive Generation: Instead of predicting units sequentially, NAR generation predicts all units in parallel within a predefined chunk, significantly speeding up the process.
- Connectionist Temporal Classification: CTC handles the alignment between the variable-length text response and the corresponding speech audio sequence, predicting a sequence of discrete units
YUthat represent the speech.
- Input: The decoder takes the hidden states
Cfrom the LLM as input. It utilizes upsampling to match the granularity of the text representations to the desired granularity of the generated speech units. - Output: The decoder outputs a sequence of discrete units
YUwhich are then synthesized into a continuous waveformYSusing a unit-based vocoderV.
5. Workflow:
During inference, the four modules work in a synchronized pipeline:
- The user’s speech is encoded by the speech encoder
E. - The speech representations are adapted by the speech adapter
Aand fed into the LLMM. - The LLM decodes the text response
YTwhile simultaneously generating hidden statesC. - The speech decoder
Dconsumes the hidden statesCto produce discrete speech unitsYUin a streaming fashion. - The vocoder
Vsynthesizes the speech units into audible waveformYS, enabling real-time speech output.
Constructing the Training Data: InstructS2S-200K
Recognizing the lack of suitable speech instruction datasets, the paper emphasizes the creation of InstructS2S-200K. This dataset addresses the unique characteristics of speech interactions, ensuring high-quality training for LLaMA-Omni. The data generation process involves:
- Instruction Rewriting: Existing text-based instructions are modified to mimic natural speech patterns. This includes:
- Adding filler words like “um”, “so”, etc.
- Converting numerical digits to spoken words (“three” instead of “3”).
- Keeping instructions concise and avoiding overly complex sentence structures.
- Response Generation: The rewritten instructions are then used to generate responses tailored for speech. The focus is on:
- Concise and to-the-point answers, avoiding lengthy explanations.
- Excluding elements unsuitable for TTS synthesis, like lists or parentheses.
- Speech Synthesis: The final stage involves converting both the rewritten instructions and their corresponding responses into speech audio using high-quality TTS models.
Evaluating LLaMA-Omni’s Capabilities
LLaMA-Omni’s performance is rigorously assessed on two primary tasks:
- Speech-to-Text Instruction Following (S2TIF): Evaluating the model’s capability to understand spoken instructions and generate accurate text responses.
- Speech-to-Speech Instruction Following (S2SIF): Measuring the system’s effectiveness in engaging in natural and low-latency speech-based interactions.
The evaluation incorporates several key metrics:
- ChatGPT Scoring: GPT-40 is employed to score the quality and relevance of the model’s responses on both content and style, providing a human-like judgment of the output.
- Speech-Text Alignment: Metrics like Word Error Rate (WER) and Character Error Rate (CER) assess the consistency between the LLM’s generated text response and the speech output transcribed from the audio waveform.
- Speech Quality: A Mean Opinion Score (MOS) prediction model, UTMOS, is used to evaluate the naturalness and clarity of the synthesized speech.
- Response Latency: A critical metric for real-time interaction, latency measures the delay between the end of the user’s speech input and the start of the system’s speech response.
The results demonstrate LLaMA-Omni’s superior performance across all these metrics, highlighting its effectiveness for low-latency, high-quality speech interaction with LLMs.
The Perfect Blend: Redefining RLHF with Mixture of Judges
Introduction
This paper introduces CGPO (Constrained Generative Policy Optimization), a novel post-training paradigm for Large Language Models (LLMs) that significantly improves upon the current standard, RLHF (Reinforcement Learning from Human Feedback). CGPO addresses two major limitations of RLHF in multi-task settings:
1. Vulnerability to Reward Hacking:
- LLMs can exploit weaknesses in preference-based reward models, optimizing for high reward values even if the outputs don’t truly align with human preferences.
- This becomes more challenging in multi-task scenarios where each reward model may have its own flaws and a uniform optimization strategy can be detrimental.
2. Contradictory Goals:
- Different tasks may have conflicting objectives, leading to compromises in performance when using a linear combination of reward models.
- A uniform RLHF optimizer setup across all tasks can be suboptimal as different tasks might benefit from different hyperparameter settings.
CGPO addresses these limitations by incorporating the following key innovations
1. Mixture of Judges (MoJs):
- Instead of relying solely on reward models, CGPO introduces two types of judges: rule-based and LLM-based.
- These judges evaluate LLM generations in real-time for constraint satisfaction, helping to detect and mitigate reward hacking behaviors.
- Examples of constraints: providing correct answers in math problems, ensuring code snippets pass unit tests, generating safe responses to harmful prompts.
2. Constrained RLHF Optimizers:
- CGPO implements three new primal-type constraint RLHF optimizers that operate independently of the dual-variable update, simplifying the process and enhancing scalability for large-scale LLM post-training.
- CRPG (Calibrated-Regularized Policy Gradient): Utilizes a calibrated reward model for better comparison across prompts and incorporates constraint regularization in the gradient update.
- CODPO (Constrained Online Direct Preference Optimization): Adapts the offline DPO method to incorporate constraints and regularizes the update to prevent likelihood reduction of positive samples.
- CRRAFT (Calibrated-Regularized Reward Ranking Finetuning): Builds upon the RAFT algorithm by filtering out constraint-violating responses and weighting chosen responses by their calibrated reward values for a more refined alignment.
3. Multi-Task Optimization Strategy:
- Unlike traditional methods that apply a unified treatment across all tasks, CGPO segregates prompts by task and employs a customized optimization strategy for each.
- This includes tailored MoJs, reward models, and hyperparameters for the constrained RLHF optimizer, allowing each task to be optimized independently without compromises from conflicting goals.
Architecture and Implementation
- CGPO first separates the prompt set into distinct task categories based on prompt nature (e.g., general chat, math reasoning, safety).
- For each task, a customized reward model is trained using relevant preference data.
- During online generation, a task-specific mixture of judges is applied to assess constraint satisfaction for each LLM output.
- Finally, a tailored constrained RLHF optimizer is used to update the model based on the reward model values and constraint satisfaction labels.
Experimental Results
- CGPO is evaluated on five tasks: general chat, instruction following, math/code reasoning, engagement intent, and safety.
- Using open-source data and the Llama3.0 70b pre-trained model, CGPO consistently outperforms baseline RLHF methods (PPO and DPO) across all tasks and benchmarks.
- Notably, CGPO effectively prevents reward hacking in coding tasks, where PPO exhibits significant performance degradation, highlighting the crucial role of MoJs.
Key contributions of the paper
- A novel primal-type constrained RL method for mitigating reward hacking in multi-task LLM post-tuning.
- Introduction of two types of judges (rule-based and LLM-based) for effective constraint satisfaction evaluation.
- Development of three new constrained RLHF optimizers (CRPG, CODPO, and CRRAFT) designed for scalability and ease of implementation.
- A pioneering multi-objective RLHF treatment strategy that optimizes each task independently with customized settings for better Pareto frontier across multiple metrics.