
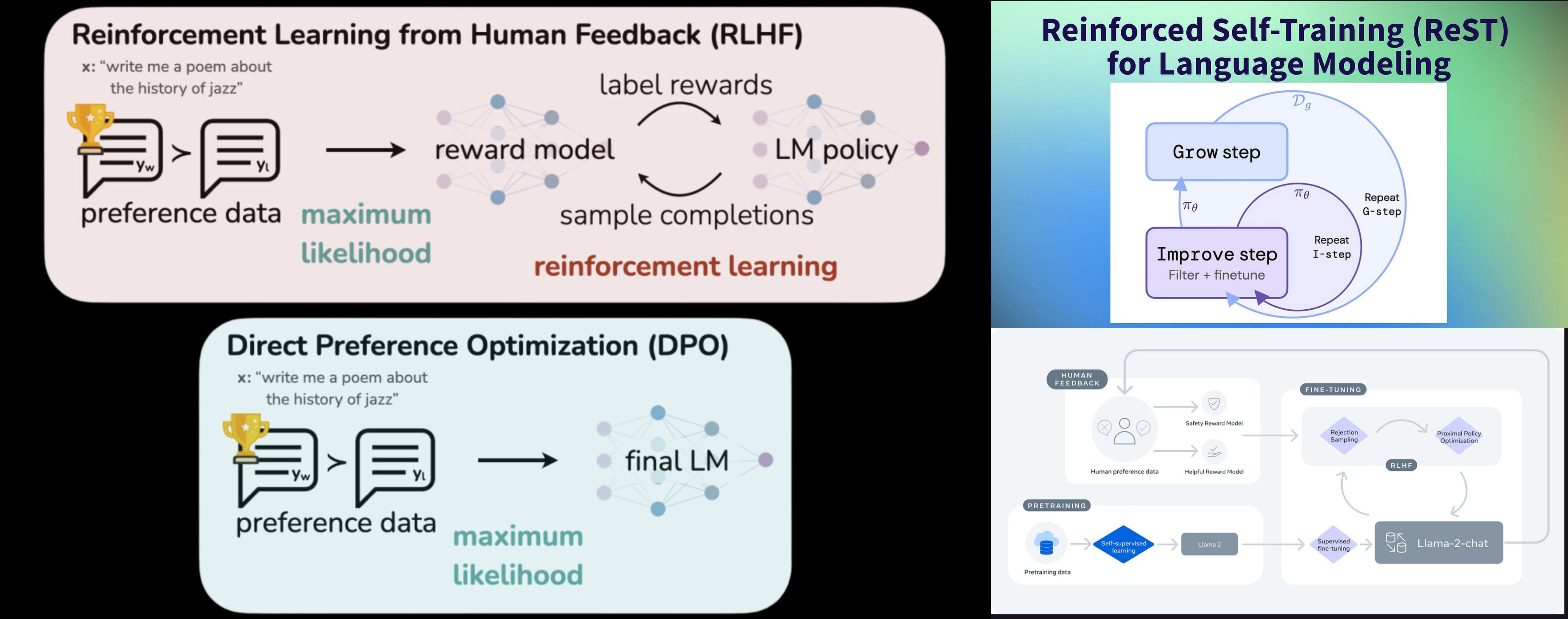
Preference Training for LLMs in a Nutshell
- Reinforcement Learning with Human Feedback
- Reinforced Self Training (ReST)
- Direct Preference Optimization
- Conclusion
- References
Large Language Models (LLMs) harness the power of unsupervised learning(self-supervised to be precise) on extensive datasets, showcasing remarkable natural language processing capabilities. However, these models exhibit inherent limitations when not trained using Reinforcement Learning with Human Feedback (RLHF). One significant drawback lies in their lack of specificity and control. Although LLMs can generate contextually relevant outputs, they might fail to precisely adhere to user instructions, resulting in technically correct yet divergent responses. The absence of a mechanism for real-time adaptation to user feedback during inference further adds to this limitation, hindering the models from refining their outputs based on corrective input.
Ethical concerns and biases also affect LLMs not trained with RLHF. These models inadvertently showcase biases present in the training data, leading to outputs that may be skewed or unfair. Additionally, their vulnerability to generating incorrect or misleading information poses challenges in contexts where accuracy is critical. Despite their contextual understanding, LLMs may struggle with commonsense reasoning and language variations, impacting their ability to provide accurate and nuanced responses. Integrating RLHF into the training process addresses these flaws by enabling the model to learn from human feedback, rectify errors, and adapt to user preferences. This iterative learning approach enhances the model’s overall performance, mitigating biases, improving accuracy, and enabling better alignment with user expectations.
In this blog, we’ll explore different ways to make Large Language Models (LLMs) better understand and respond to users’ preferences. Firstly, we’ll talk about the most talked method called Reinforcement Learning with Human Feedback (RLHF), using a reinforcement learning optimization called Proximal Policy Optimization (PPO). This helps the model learn from user feedback and improve its responses over time.
Next, we’ll look at some modifications done by Meta for training their LLama-2 models. They use two reward models instead of one, making the model more sensitive to users’ preferences. They also use rejection sampling to enable the model generate responses with maximum possible rewards. Lastly, we’ll discuss a few alternatives to RLHF, like Direct Preference Optimization(DPO), and Reinforced Self-Training which mitigate the use of reward models and directly optimizing the policy(LLM) using the preference data.
Reinforcement Learning with Human Feedback
RLHF was introduced by OpenAI in the paper titled “Training language models to follow instructions with human feedback”. The authors describe their efforts in advancing the alignment of language models by training them to align with user intentions. They emphasize the importance of aligning language models with both explicit and implicit user intentions, such as following instructions, staying truthful, and avoiding biases or toxicity. The primary focus is on fine-tuning approaches, specifically using Reinforcement Learning from Human Feedback (RLHF) with Proximal Policy Optimization (PPO) to align the GPT-3 model to a broad range of written instructions.
The process involves hiring contractors to label data, collecting datasets of human-written demonstrations and comparisons, training reward models, and fine-tuning the model to maximize the reward using PPO. The resulting model, called InstructGPT, aligns with the preferences of a specific group of people, as opposed to a broader notion of “human values.” Evaluation involves labeler ratings, automatic evaluations on NLP datasets, and comparisons between InstructGPT and GPT-3. Notable findings include labeler preferences for InstructGPT outputs, improvements in truthfulness, small gains in toxicity reduction, and generalization to preferences of held-out labelers. While exact training details for the best performing models like ChatGPT and GPT-4 haven’t been released by OpenAI, the models’ ability to adapt excellently to specific user preferences hints at RLHF as the core methodology behind the behaviour.
A model having a behavior like ChatGPT is usually trained in three steps, unsupervised continual pretraining on a very large corpus followed by supervised finetuning on a high quality instruction-response pair dataset. At Last, RLHF comes into picture which is implemented as follows:
- Data Collection
Collect a dataset of human-labeled comparisons, where human annotators rank different model-generated outputs based on their quality or preference.
- Reward Model (RM) Training
Create a reward model by training it on the comparison data. The reward model predicts the preferences of human annotators by learning which model-generated outputs they prefer in different scenarios. The reward model in this case is also an LLM with the last token predictor replaced with a softmax layer which predicts a scalar reward for an instruction-response pair.
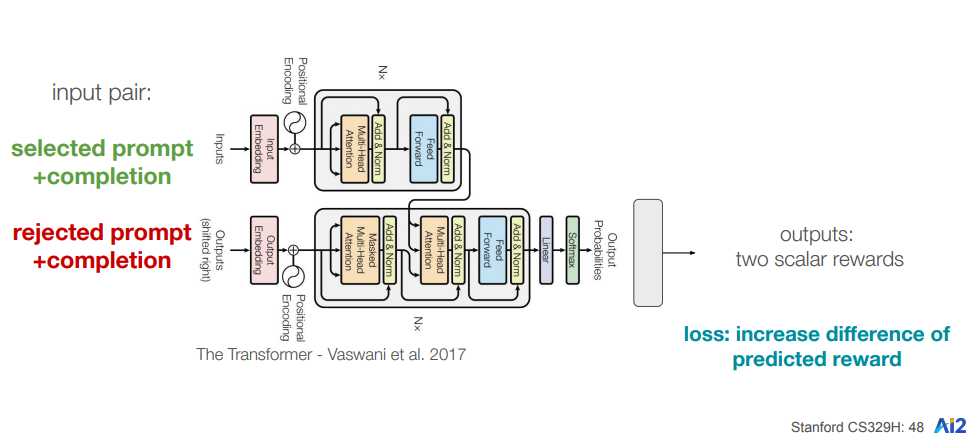
The reward model accepts an instruction(prompt) and two responses for it at a time. The loss function for the model is based on the objective of increasing the difference of rewards between the two pairs which can be shown as follows:
Lreward = log(1 + e(Rrejected - Rchosen))
Note: Training reward models in poses several challenges. One significant hurdle lies in obtaining high-quality and diverse human feedback data that accurately reflects the nuances of user preferences. Designing comparison datasets that effectively capture the subtle distinctions in model-generated outputs requires careful consideration, as human annotators might interpret and rank responses differently. Additionally, ensuring consistency and reliability among human labelers is challenging, as subjective judgments may vary. Managing the potential bias introduced by the preferences of a specific group of labelers and addressing the issue of conflicting feedback further complicates the reward model training process. Striking a balance between collecting sufficiently rich data for effective training and avoiding biases that may arise in the annotation process remains a persistent challenge in achieving robust and reliable reward models for RLHF.
- Policy(LLM) Update using PPO
The objective function for PPO is as follows:
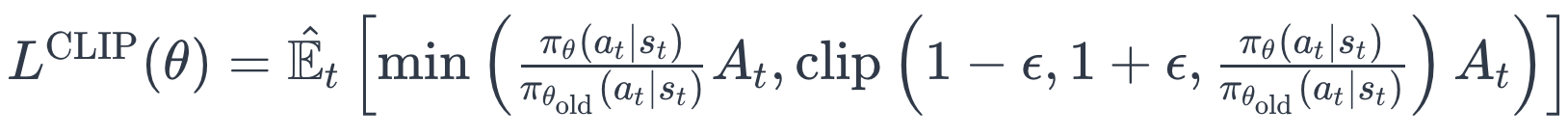
where πθ(at∣st) is the probability distribution for the current policy(LLM being updated) and πθold(at∣st) is the probability distribution for the original(LLM at the start of the training) model and At is the advantage function for the policy which is basically Rewardcurrent - Rewardold in this context. The ppo objective function is clipped by a value ϵ so as to prevent the policy from getting updated catastrophically from the previous policy which can destabilize the training.
Note that we are not adding the (cumulative future reward over time) term here because of the limited setting of RLHF as the instruction can keep varying across each data point and might not be in a sequential chat sequence mode. If we still want to incorporate the future rewards given that the training dataset is in a dialogue setting instead of single instruction-response setting, We can modify the advantage function as Rewardcurrent+future - Rewardold, where the first term is a sum of rewards for model responses beginning from now until the conversation ends.
Now that we have discussed the objective function, the policy(the model to be trained) is updated using an optimization algorithm such as gradient descent as follows:
θnew = θold +α⋅∇θLclip(θ)
Now, Meta has implemented its own version of RLHF for Llama-2 models. Let’s discuss the key differences as follows:
Two reward models instead of One
Llama-2 uses a dual reward model approach to enhance the quality and safety of its generated output. The first reward model assesses the usefulness of the generated content for the user, ensuring it aligns with the user’s needs and preferences. Meanwhile, the second reward model focuses on safety, evaluating the generated output for potential harmful or toxic content. By utilizing these two distinct reward models, Llama-2 aims to deliver high-quality output that not only meets user expectations but also prioritizes user safety. This dual-model strategy enables Llama-2 to strike a balance between user satisfaction and content safety, providing tailored and secure results.
Rejection Sampling
Rejection sampling, in contrast to the traditional approach of taking only one sample per iteration, involves generating multiple samples. Among these samples, the one with the highest reward is selected as the new “gold standard” for that iteration. This chosen sample serves as the reference for fine-tuning the model in the next iteration. The iterative nature of rejection sampling, by considering and reinforcing the highest-reward samples, can significantly increase the maximum reward observed during the fine-tuning process. This approach aims to guide the model towards generating more favorable and high-quality outputs over successive iterations.
Reinforcement Learning from Human Feedback (RLHF) methods often use online training, where the model learns by continuously sampling and scoring new examples. However, this can be computationally demanding and is prone to reward hacking. Alternatively, offline methods learn from a fixed dataset, making them more computationally efficient and less susceptible to certain problems. However, the success of offline methods heavily depends on having a well-curated dataset. Carefully selecting and preparing the dataset becomes crucial for the effectiveness of offline methods, as their performance gains over traditional supervised learning might be limited without a high-quality dataset. Let’s discuss one such approach which uses a simpler offline RL training approach.
Reinforced Self Training (ReST)
Decoupling Dataset Growth and Policy Improvement:
- Divides the RL pipeline into separate offline stages, namely Grow and Improve.
- Begins with training an initial model M on dataset D(continual pretraining & supervised finetuning).
Grow Step:
- Creates a new dataset Dg by sampling from the model and augmenting the initial training dataset.
- Annotates Dg with a reward model R.
Improve Step:
- Defines a filtering function F to include samples with rewards higher than a threshold t.
- Fine-tunes the current best policy on the filtered data using a reward-weighted loss J(θ).
- Iterates over Improve steps with increasing filtering thresholds.
Now the objective function J(θ) can either be used as another supervised finetuning step on D𝑔 or be used as a Reinforcement Learning Objective Function such as Actor Critic Method or Deep Q-Learning explained in my previous blogs. This method essentially still requires training a reward model but the policy update is now done in an offline manner as compared to the online manner in the previous approach. This reduces the training time and reward hack issue to some extent.
Now let’s discuss a method which completely avoids using Reinforcement Learning and usage of a reward model.
Direct Preference Optimization
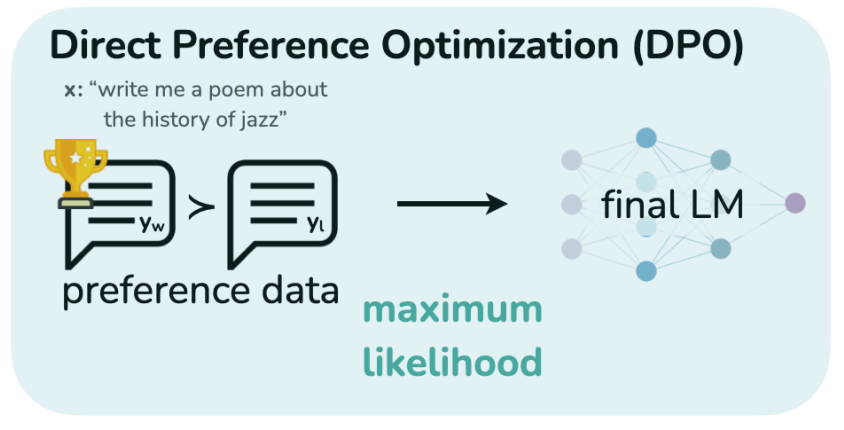
Direct Preference Optimization (DPO) is a straightforward algorithm for training language models from human preferences without relying on reinforcement learning. Unlike other methods, DPO directly optimizes the policy using a binary cross entropy objective, without the need to explicitly learn a reward function or sample from the policy during training. The algorithm increases the likelihood of preferred responses over dispreferred ones, preventing model degeneration with dynamic importance weights. DPO employs a theoretical preference model to measure how well a reward function aligns with empirical preference data. Experiments demonstrate that DPO is as effective as existing methods, such as PPO-based RLHF, for tasks like sentiment modulation, summarization, and dialogue, even with large language models up to 6 billion parameters.
Essentially, DPO estimates the reward function in the supervised model objective function itself thus preventing the need of a separate reward function and Reinforcement Learning mechanism. The loss function of DPO is as follows:

where,
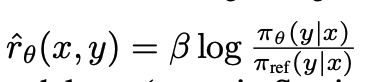
In Direct Preference Optimization (DPO), the loss function implicitly defines the reward for a language model in comparison to a reference model. This loss function’s gradient aims to increase the likelihood of preferred completions yw while decreasing the likelihood of dispreferred completions yl. Notably, the examples are weighted based on how much higher the implicit reward model $rˆθ$ rates the dispreferred completions, scaled by β. This scaling factor accounts for the degree of incorrect ordering by the implicit reward model, considering the strength of the KL constraint. Essentially, DPO fine-tunes the language model based on preferences, adjusting its output probabilities to align better with human preferences without needing to train a reward model thus making the process cost effective and without needing a reinforcement learning mechanism thus making the process less time consuming. Results show that DPO still achieves results very close to RLHF and thus fits best in scenarios where there is a dearth of preference training data or compute.
Conclusion
In this discussion, we covered various aspects of reinforcement learning from human feedback (RLHF), exploring methods like PPO and algorithms such as Llama-2, ReST, and DPO. From training reward models to addressing challenges in RLHF, we gained insights into diverse approaches for aligning language models with human preferences. These methods, including ReST’s decoupling of dataset growth and policy improvement and DPO’s direct optimization from preferences, reflect the dynamic landscape of language model training.